聚合概览
Aggregations
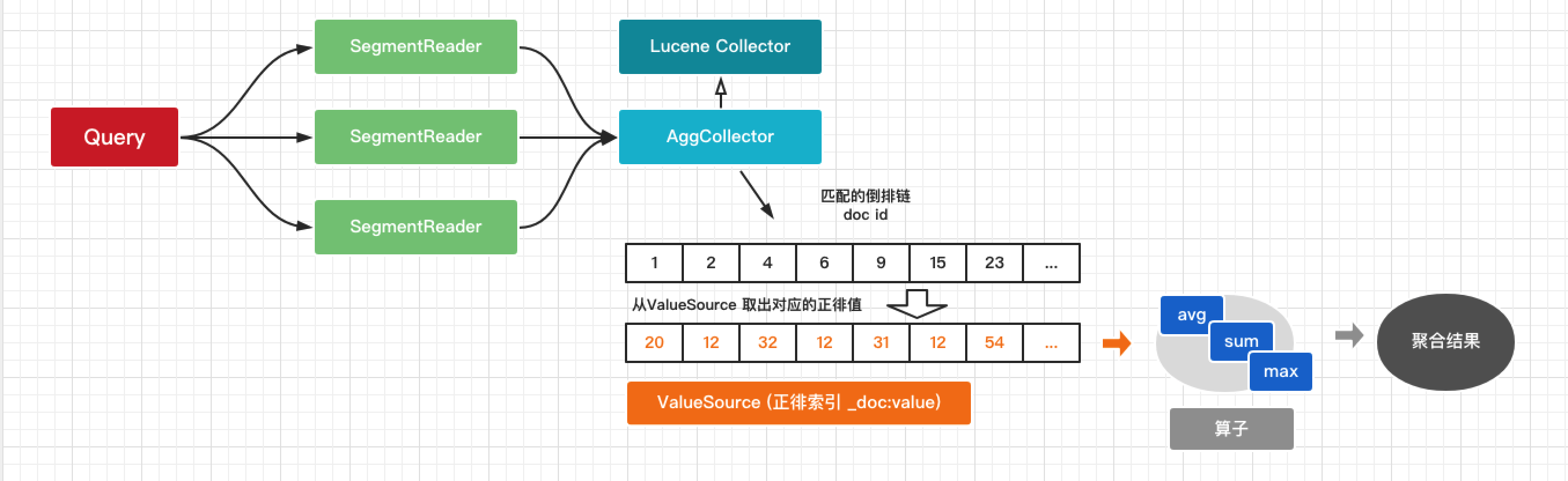
Elasticsearch提供了Aggregation聚合功能辅助我们进行数据的分析,原理是基于查询(Query)在倒排链的形成过程中增加了二次聚合计算过程。如下图
- 执行一个Query。在检索过程中,底层的 Lucene Collector 会为匹配到的文档形成一条链式结构。doc1,doc2,doc4 ...
- AggCollector作为一个 Filted Collector,根据取到的doc id从正排索引拿出字段值并丢给算子执行汇总计算。
了解了基础原理,我们便可以理解在使用聚合分析时:
- 只有开启正排的索引才能进行聚合计算, doc_value=true
- 聚合计算和Query的size无关,因为它发生在倒排检索阶段,通常我们可以设置size=0来优化性能。
- 聚合计算的代价由Query匹配的文档数决定(倒排链越长代价越高,涉及到抓取和计算),如计算量过大可以设置query 的 terminate_after 减少匹配文档数。
- 聚合计算过程发生在算分的前一阶段,也就是和算分无关,通常我们可以通过 Constant Score Query 或 Filter 子句关闭算分,降低倒排查询代价。
概念
- Bucketing (桶聚合) 满足特定条件的文档的集合。
- Metric (指标聚合) 对桶内的文档进行统计计算。
- Pipeline (管道聚合) 聚合其他聚合的输出及其相关度量的聚合。
- Matrix (矩阵聚合) 对多个字段进行操作并根据从请求的文档字段中提取的值生成矩阵结果的聚合族。
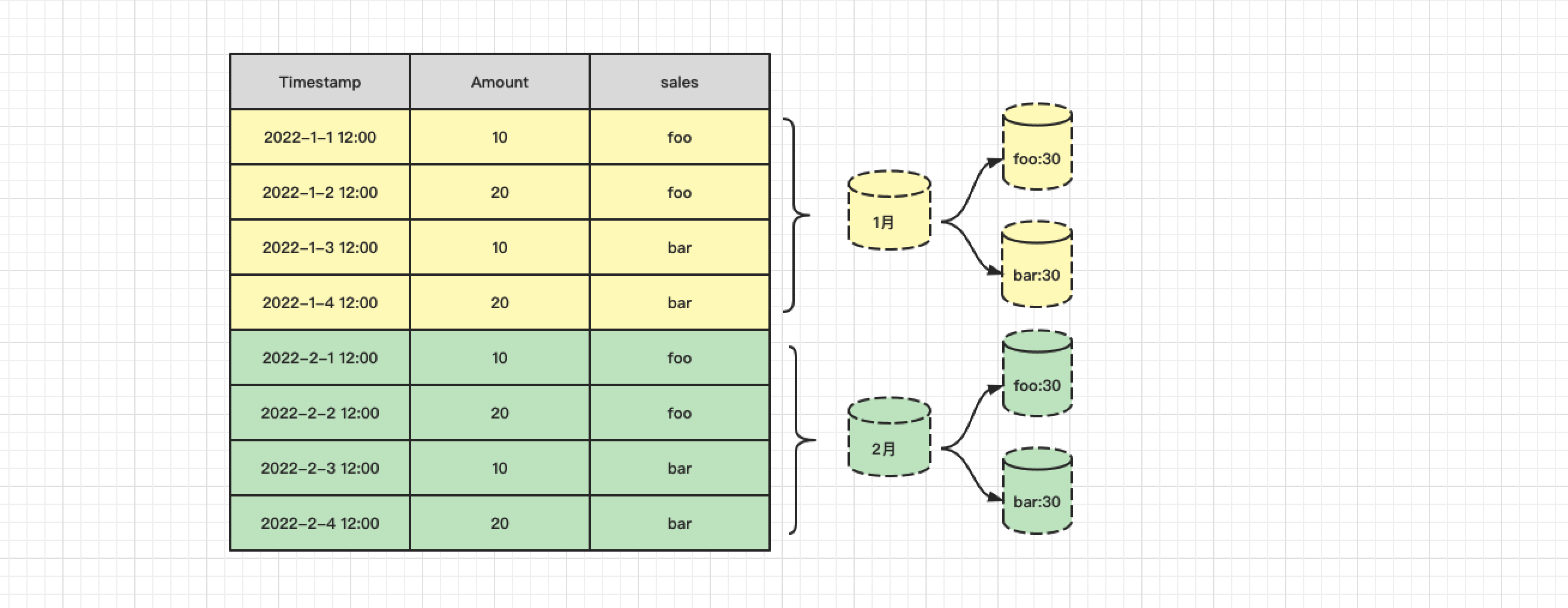
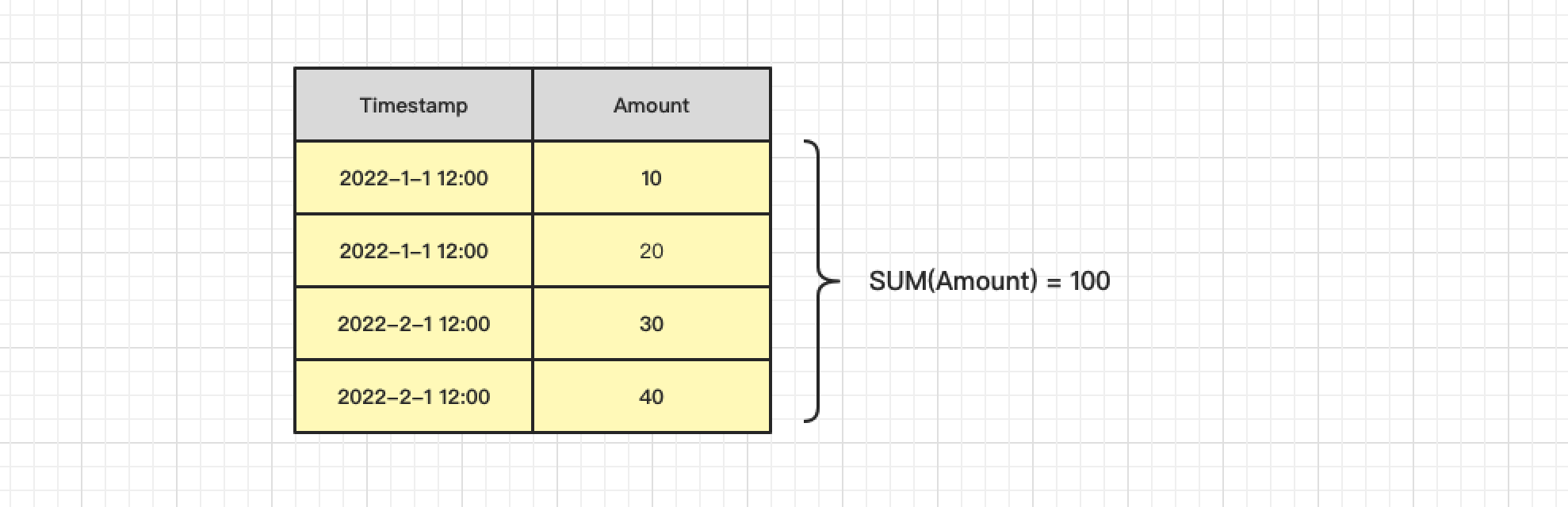
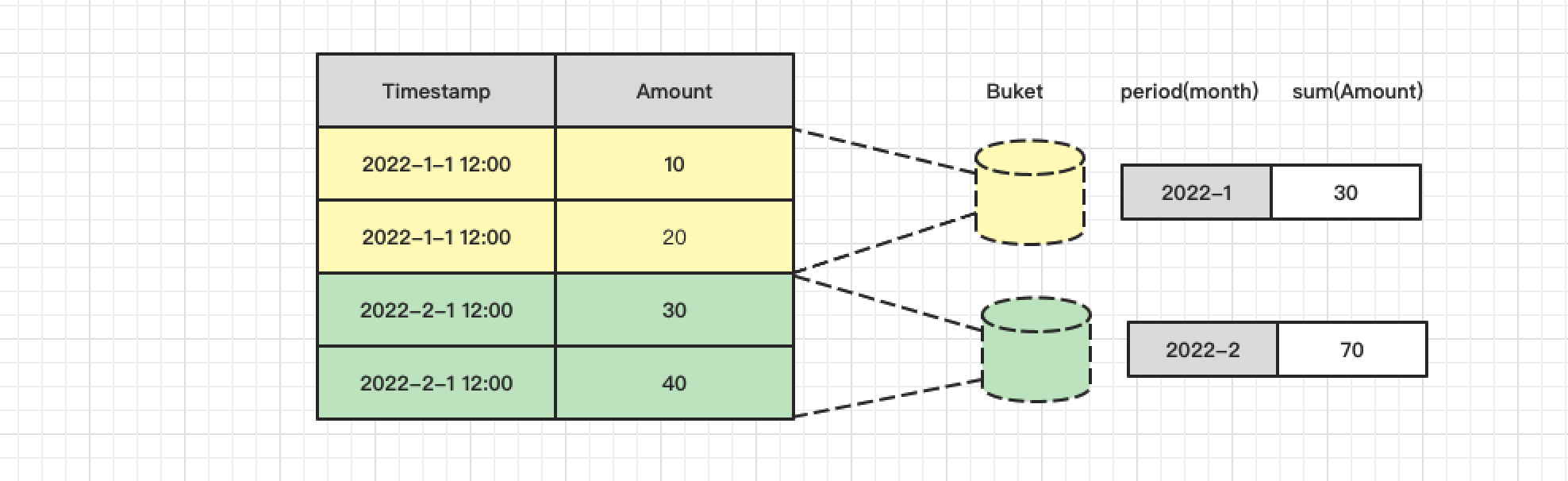
例如有一组商品的销售数据。
- 指标聚合:统计全部的总金额。
- 桶聚合:增加按月汇总。
- 管道聚合:基于按月的统计结果再按销售员的统计