移动平均聚合 moving_avg
Moving Average Aggregation
给定一系列有序的数据,移动平均值聚合将在数据上滑动一个窗口,并显示该窗口的平均值。例如,给定数据[1,2,3,4,5,6,7,8,9,10],我们可以计算窗口大小为5的简单移动平均值,如下所示:
- (1 + 2 + 3 + 4 + 5) / 5 = 3
- (2 + 3 + 4 + 5 + 6) / 5 = 4
- (3 + 4 + 5 + 6 + 7) / 5 = 5
- etc
Moving averages 是平滑连续数据的简单方法。移动平均值通常应用于基于时间的数据,如股价或服务器指标。平滑可用于消除高频波动或随机噪声,这使得较低频率的趋势更容易可视化,例如季节性。
语法
{
"moving_avg": {
"buckets_path": "the_sum",
"model": "holt",
"window": 5,
"gap_policy": "insert_zeros",
"settings": {
"alpha": 0.8
}
}
}
moving_avg 参数
| 参数名 | 描述 | 是否必须 | 默认值 |
|---|---|---|---|
| buckets_path | 桶的路径 | 必选 | |
| model | 我们希望使用的移动平均加权模型 | 必选 | simple |
| gap_policy | 在数据中发现差距时应用的策略 | 可选 | insert_zeros |
| window | 在直方图上“滑动”的窗口大小。 | 可选 | 5 |
| minimize | 如果模型应在算法上最小化 | 可选 | false |
| settings | 特定于model的设置,内容因指定的model而异。 | 可选 |
movingavg agg必须嵌入到histogram或date_histogram aggregation中。它们可以像任何其他metric aggregation一样嵌入:
OST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg":{
"moving_avg":{ "buckets_path": "the_sum" }
}
}
}
}
}
移动平均值是通过在字段上指定histogram或date_histogram来构建的 上述聚合的示例响应如下
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"my_date_histo": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"the_sum": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"the_sum": {
"value": 60.0
},
"the_movavg": {
"value": 550.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"the_sum": {
"value": 375.0
},
"the_movavg": {
"value": 305.0
}
}
]
}
}
}
Models
moving_avg聚合包括四个不同的移动平均“模型”。主要区别在于窗口中的值是如何加权的。随着数据点在窗口中变得“older”,它们的权重可能会有所不同。这将影响该窗口的最终平均值。
使用模型参数指定模型。某些model可能具有在settings参数中指定的可选配置。
Simple
simple model计算窗口中所有值的总和,然后除以窗口的大小。它实际上是窗口的简单算术平均值。简单模型不执行任何时间相关加权,这意味着简单移动平均值的值往往“滞后”于实际数据。
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg":{
"moving_avg":{
"buckets_path": "the_sum",
"window" : 30,
"model" : "simple"
}
}
}
}
}
}
一个 simple model 的模型没有需要配置的特殊设置
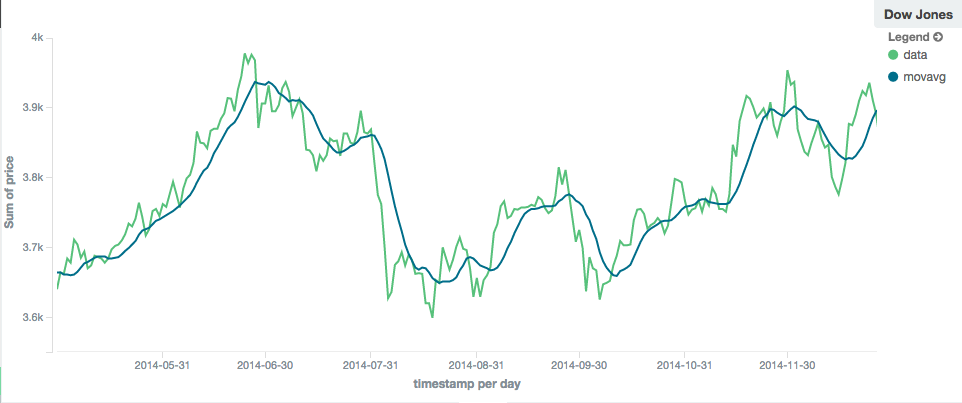
窗口大小可以改变移动平均线的行为。例如,一个小窗口(“窗口”:10)将密切跟踪数据,仅平滑小范围波动:
图1.窗口大小为10的移动平均线
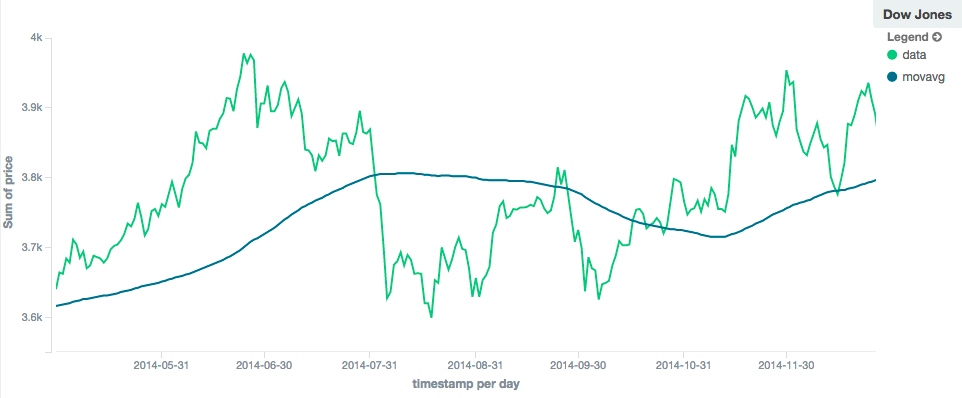
相比之下,具有较大窗口(“窗口”:100)的simple moving average将平滑所有较高频率的波动,只留下低频的长期趋势。它也倾向于“滞后”于实际数据一大截:
图2.窗口大小为100的移动平均线
Linear
线性模型为序列中的点分配线性权重,使得“较旧”的数据点(例如,窗口开始处的数据点)对总平均值的贡献线性较小。线性加权有助于减少数据平均值之后的“滞后”,因为旧点的影响较小。
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg": {
"moving_avg":{
"buckets_path": "the_sum",
"window" : 30,
"model" : "linear"
}
}
}
}
}
}
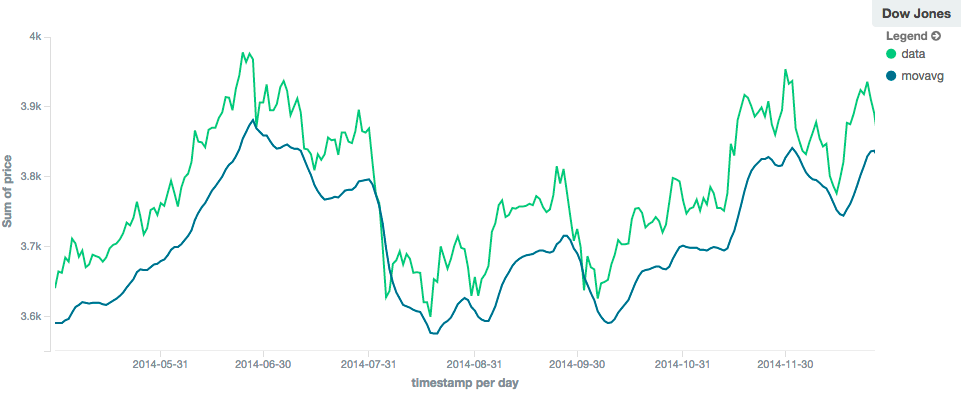
与简单模型一样,窗口大小可以改变移动平均线的行为。例如,一个小窗口(“窗口”:10)将密切跟踪数据,仅平滑小范围波动:
图3.窗口大小为10的线性移动平均值
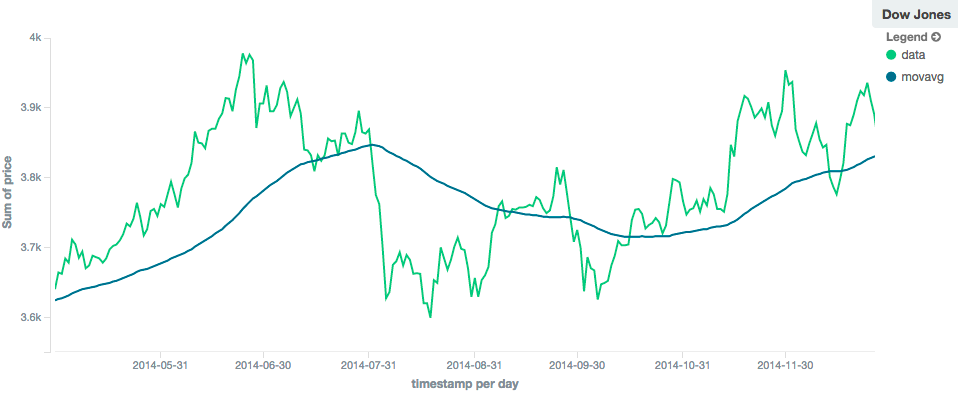
相比之下,具有较大窗口(“窗口”:100)的线性移动平均线将平滑所有较高频率的波动,只留下低频的长期趋势。它也倾向于“滞后”于实际数据相当大的数量,尽管通常比简单模型要少:
图4.窗口大小为100的线性移动平均值
EWMA (Exponentially Weighted)
ewma模型(又称“单指数”)与线性模型相似,只是较旧的数据点变得不那么重要,而不是线性不那么重要。重要性衰减的速度可以通过alpha设置来控制。较小的值会使权重衰减缓慢,从而提供更大的平滑度,并考虑到窗口的较大部分。较大的值会使权重快速衰减,从而减少旧值对移动平均值的影响。这往往会使移动平均线更接近地跟踪数据,但平滑度较低。
alpha的默认值为0.3,该设置接受0-1(含0-1)之间的任何浮动。
EWMA模型可以最小化
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg": {
"moving_avg":{
"buckets_path": "the_sum",
"window" : 30,
"model" : "ewma",
"settings" : {
"alpha" : 0.5
}
}
}
}
}
}
}
图5.EWMA,窗口大小为10,alpha=0.2

图6.EWMA,窗口大小为10,alpha=0.7

Holt-Linear
holt model (又名“双指数”)包含了跟踪数据趋势的第二个指数项。当数据具有潜在的线性趋势时,单指数表现不佳。双指数模型内部计算两个值:“level”和“trend”。
级别计算类似于ewma,是数据的指数加权视图。不同之处在于,使用了先前平滑的值而不是原始值,从而使其保持接近原始序列。趋势计算着眼于当前值和上次值之间的差异(例如,平滑数据的斜率或趋势)。趋势值也按指数加权。
值通过乘以水平和趋势分量产生。
alpha的默认值为0.3,beta为0.1。这些设置接受0-1(含0-1)之间的任何浮动。
Holt线性模型可以最小化
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg": {
"moving_avg":{
"buckets_path": "the_sum",
"window" : 30,
"model" : "holt",
"settings" : {
"alpha" : 0.5,
"beta" : 0.5
}
}
}
}
}
}
}
实际上,alpha值在holt中的表现与ewma非常相似:较小的值产生更多的平滑和更多的滞后,而较大的值产生更紧密的跟踪和更少的滞后。beta的值通常很难看出。小值强调长期趋势(例如整个系列中的恒定线性趋势),而大值强调短期趋势。当您预测值时,这将变得更加明显。
图7.Holt线性移动平均值,窗口大小为100,alpha=0.5,beta=0.2

图8.Holt线性移动平均值,窗口大小为100,alpha=0.5,beta=0.7

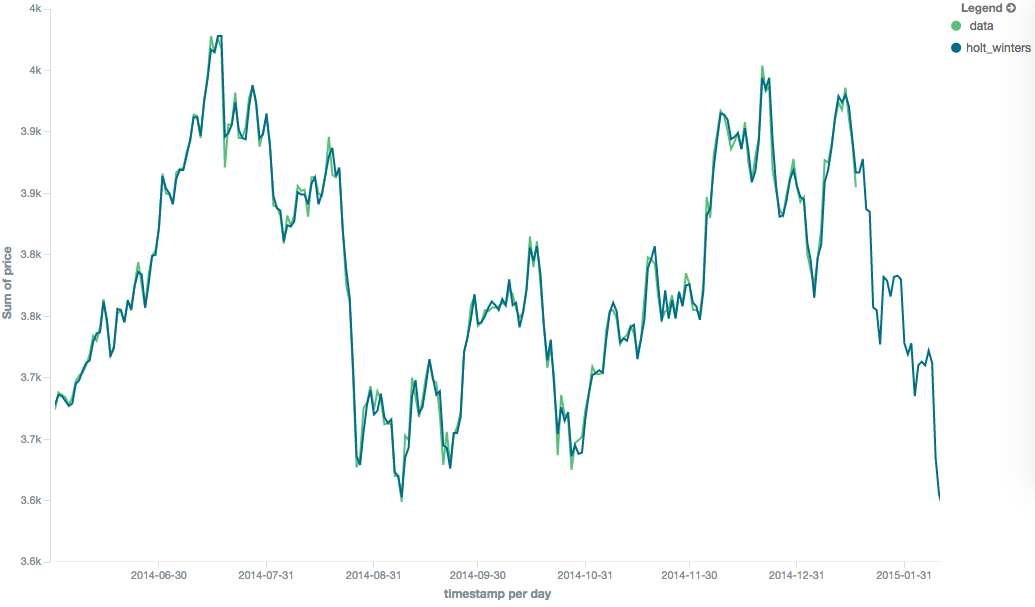
Holt-Winters
holt_winters模型(又称“三指数”)包含第三个指数项,它跟踪数据的季节性方面。因此,这种聚合基于三个组成部分:"level", "trend","seasonality"。
level和trend计算与holt相同。seasonality计算着眼于当前点和前一个周期点之间的差异。
Holt-Winters 需要比其他移动平均线多一点的handholding。您需要指定数据的“周期性”:例如,如果您的数据每7天有一次周期性趋势,您可以设置周期:7。同样,如果有月度趋势,您也可以将其设置为30。目前没有周期性检测,但这是为将来的增强而计划的。
"Cold Start"
不幸的是,由于Holt-Winters的性质,它需要两段时间的数据来“bootstrap”算法。这意味着你的窗口必须至少是你的周期的两倍。否则将引发异常。这也意味着Holt-Winters不会为前2*周期桶发出值;当前算法不进行反向预测。
图9.Holt-Winters显示了一个“冷”启动,其中没有发出任何值
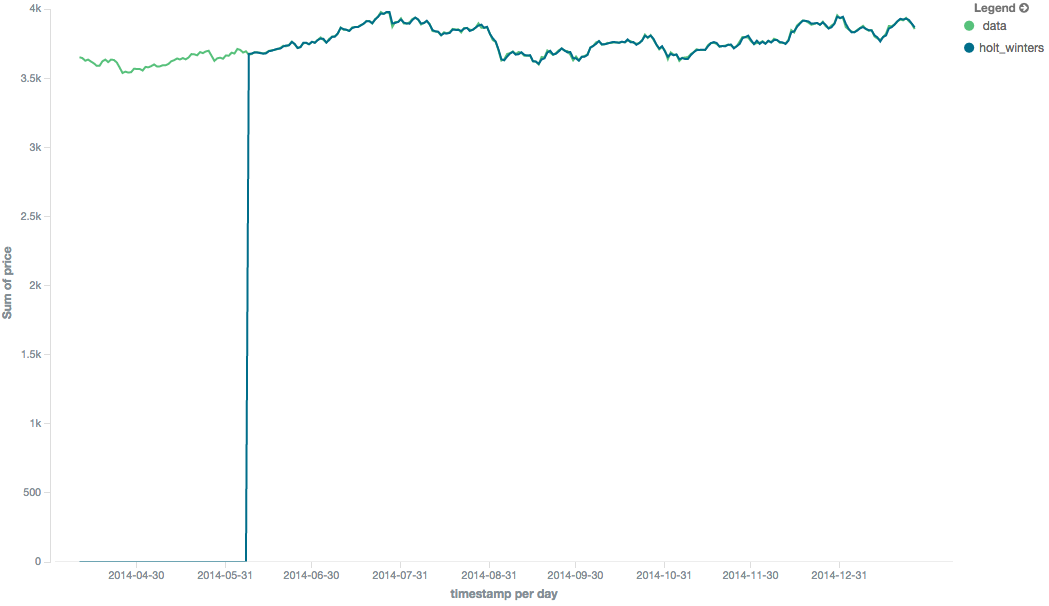
因为“cold start”掩盖了移动平均线的样子,所以Holt-Winters的其余图像被截断,以不显示“冷开始”。请注意,这将始终出现在移动平均线的开头!
Additive Holt-Winters
默认情况下,添加季节性;也可以通过设置“type”:“add”来指定。当季节性影响增加到您的数据中时,首选此品种。E、 g.你可以简单地减去季节性影响,将数据“去季节化”为一个平稳的趋势。
alpha和gamma的默认值为0.3,而beta为0.1。这些设置接受0-1(含0-1)之间的任何浮动。句点的默认值为1。
可最小化加法Holt-Winters模型
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg": {
"moving_avg":{
"buckets_path": "the_sum",
"window" : 30,
"model" : "holt_winters",
"settings" : {
"type" : "add",
"alpha" : 0.5,
"beta" : 0.5,
"gamma" : 0.5,
"period" : 7
}
}
}
}
}
}
}
图10.Holt-Winters移动平均值,窗口大小为120,α=0.5,β=0.7,γ=0.3,周期=30
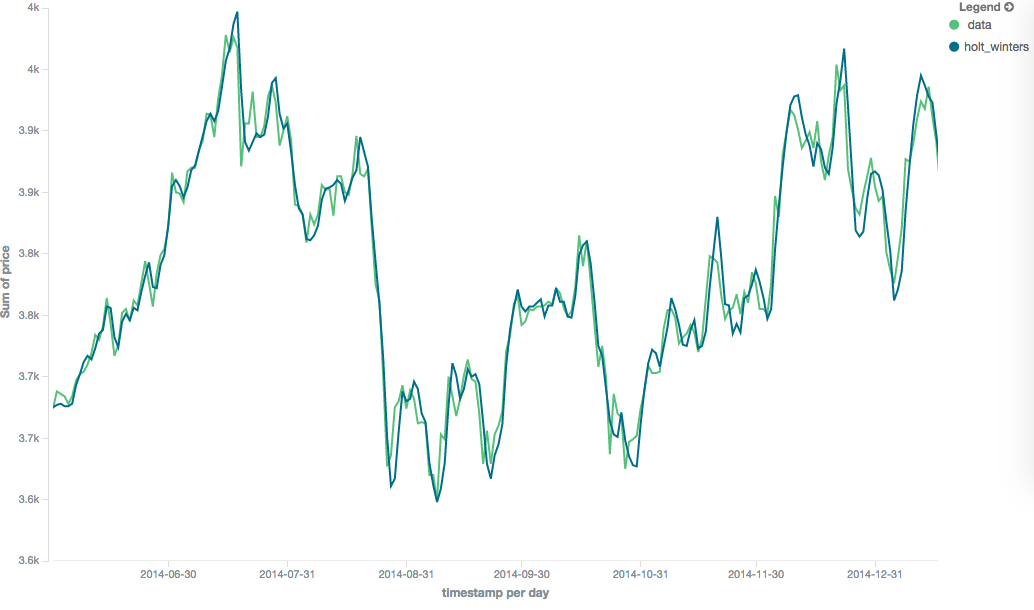
Multiplicative Holt-Winters
Multiplicative 通过设置“type”:“mult”来指定。当季节性影响与您的数据相乘时,首选该类型。
alpha和gamma的默认值为0.3,而beta为0.1。这些设置接受0-1(含0-1)之间的任何浮动。句点的默认值为1。
Multiplicative Holt-Winters模型可以最小化
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg": {
"moving_avg":{
"buckets_path": "the_sum",
"window" : 30,
"model" : "holt_winters",
"settings" : {
"type" : "mult",
"alpha" : 0.5,
"beta" : 0.5,
"gamma" : 0.5,
"period" : 7,
"pad" : true
}
}
}
}
}
}
}
Prediction
所有移动平均线模型都支持“预测”模式,该模式将尝试根据当前平滑的移动平均线推断未来。根据模型和参数,这些预测可能准确,也可能不准确。
通过向任何移动平均值聚合添加预测参数,指定要附加到系列末尾的预测数,可以启用预测。这些预测将以与您的存储桶相同的间隔进行
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg": {
"moving_avg":{
"buckets_path": "the_sum",
"window" : 30,
"model" : "simple",
"predict" : 10
}
}
}
}
}
}
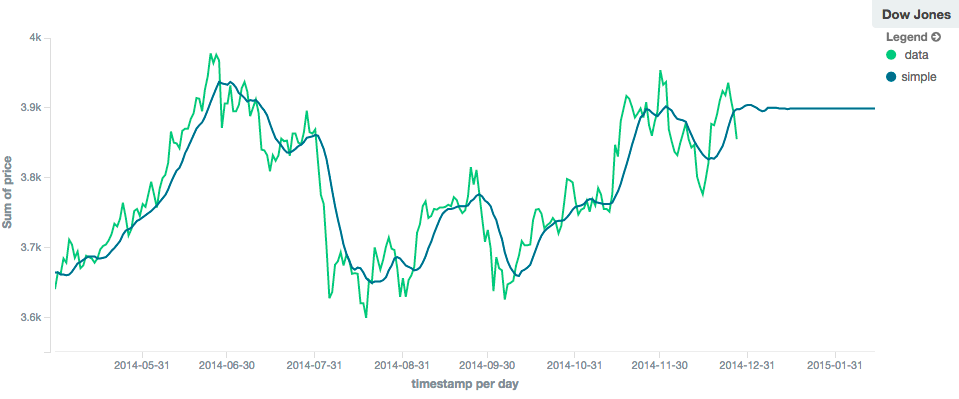
simple、 linear 、ewma 模型都产生“flat”预测:它们基本上收敛于序列中最后一个值的平均值,产生flat:
图11.窗口大小为10的简单移动平均值,预测值=50
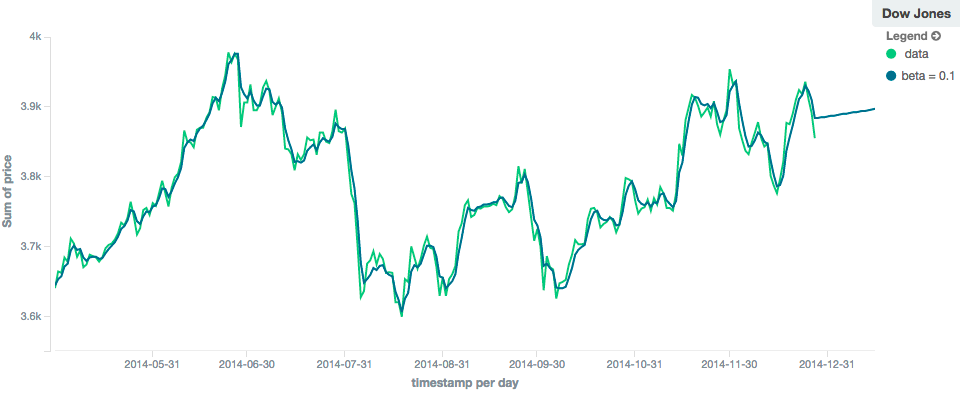
相比之下,霍尔特模型可以根据局部或全球恒定趋势进行推断。如果我们设置了一个高的贝塔值,我们可以根据局部恒定趋势进行推断(在这种情况下,预测是向下的,因为系列末尾的数据是向下的):
图12.Holt线性移动平均值,窗口大小为100,预测值=20,α=0.5,β=0.8

相比之下,如果我们选择一个小的测试版,预测是基于全球恒定趋势。在这个系列中,全球趋势略为积极,因此预测出现了急u形转弯,并开始出现正斜率
图13.窗口大小为100的双指数移动平均值,预测值=20,alpha=0.5,beta=0.1
holt_inters模型具有提供最佳预测的潜力,因为它还将季节波动纳入模型:
图14.Holt-Winters移动平均值,窗口大小为120,预测值=25,α=0.8,β=0.2,γ=0.7,周期=30
Minimization
某些模型(EWMA、Holt Linear、Holt Winters)需要配置一个或多个参数。参数选择可能很棘手,有时不直观。此外,这些参数中的小偏差有时会对输出移动平均值产生剧烈影响。
因此,三个“可调”模型可以在算法上最小化。最小化是一个调整参数的过程,直到模型生成的预测与输出数据紧密匹配。最小化不是完全可靠的,并且可能会受到过度拟合的影响,但它通常比手动调整效果更好。
默认情况下,ewma和holt_liner禁用最小化,而holt_inters默认情况下启用最小化。最小化对Holt-Winters最有用,因为它有助于提高预测的准确性。EWMA和Holt Linear不是很好的预测工具,主要用于平滑数据,因此最小化在这些模型上不太有用。
通过最小化参数启用/禁用最小化
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg": {
"moving_avg":{
"buckets_path": "the_sum",
"model" : "holt_winters",
"window" : 30,
"minimize" : true,
"settings" : {
"period" : 7
}
}
}
}
}
}
}
启用时,最小化将找到alpha、beta和gamma的最佳值。用户仍应为窗口、时段和类型提供适当的值。