
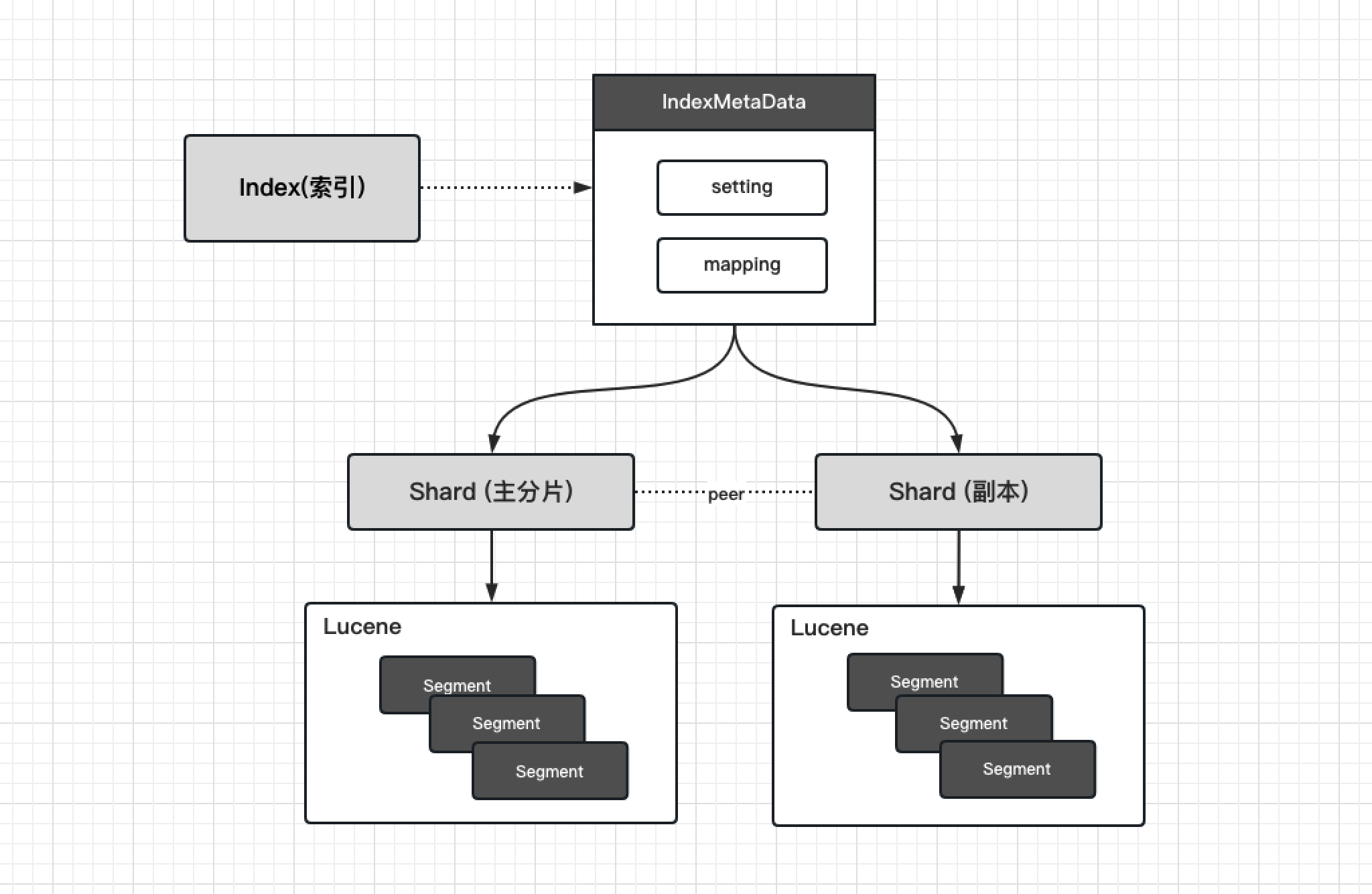
索引与分片
Elasticsearch中的每个索引都被分成一个或多个分片,每个分片可以跨多个节点复制,以防止硬件故障。
概念
- 索引(INDEX):可以理解为一个文档集合的描述文件
- setting 定义了该索引有多少个分片和副本。
- mapping 定义了索引基础的字段结构。
- 索引的描述元数据(IndexMetaData)通常物理存储占比很小,以内存的形态记录在集群状态中。
- 分片(SHARD): 真实的数据写入与查询载体。
- 写入时先路由到主分片构建成真实的lucene索引,再将操作分发给副本构建成对等的索引。
- 查询时从lucene检索出数据并交由上层映射成数据返回给用户。
- 分片的存储会随着数据的增加而增大,因此面向不同场景设置合理的分片数目是我们需要关心的。
选择合适的分片数和副本数
1. 通用场景
在纳速云平台,如果您的数据量在GB级(小于1TB),可以参考以下通用方案:
- 单分片不超过
30GB。 - 单分片的最大文档数量不超过
20亿。 - 至少设置1个副本以保证高可用性。
2. 垂搜场景
垂直搜索是针对某一行业的专业搜索,例如电商搜索、音乐搜索、站内搜索、问答搜索,该场景往往对并发量及查询延迟有较高的要求。我们可在通用方案的基础上参考以下建议:
- 分片数:竟可能的降低分片数。
- 副本数:索引的查询响应及吞吐量取决于分片数,设置在1~8之间,逐步调整以满足业务效果为准。
注意
词频是ES计算相关性的重要因素,当大量的分片上只维护了很少的数据时,词频的统计信息过于分散将导致最终的文档相关性较差。
3. 大规模以及日益增长的时序场景
如有时序特性的日志场景、指标监控场景,该场景的特性为单日写入量大,数据存储具备周期性,且有可能存储较长的时间。
- 索引按天创建,并通过生命周期管理控制数据增长。
- 分片数:索引的写入速率及吞吐量取决于分片数,设置在1~8之间,逐步调整以满足业务效果为准。
- 副本数:设置为1。
tip
如能承受丢失数据的风险,副本数可设置为0
4. 海量数据统计分析场景
如网站访问统计、销售数据分析、大屏展示等。该场景注重计算,数据呈明显的冷热特质。近期数据分析频率高,需要较快的实时性展示,历史数据使用频率低,可承受较长的等待或以异步报告的形式呈现给用户。
- 索引按天创建,并通过生命周期管理控制数据增长。
- 分片数:竟可能的降低分片数。
- 副本数:设置为1。
结语
在分片分配上并没有一刀切的答案,本文仅供参考价值,实际生产中大家还是要多测试,以上线效果为准。