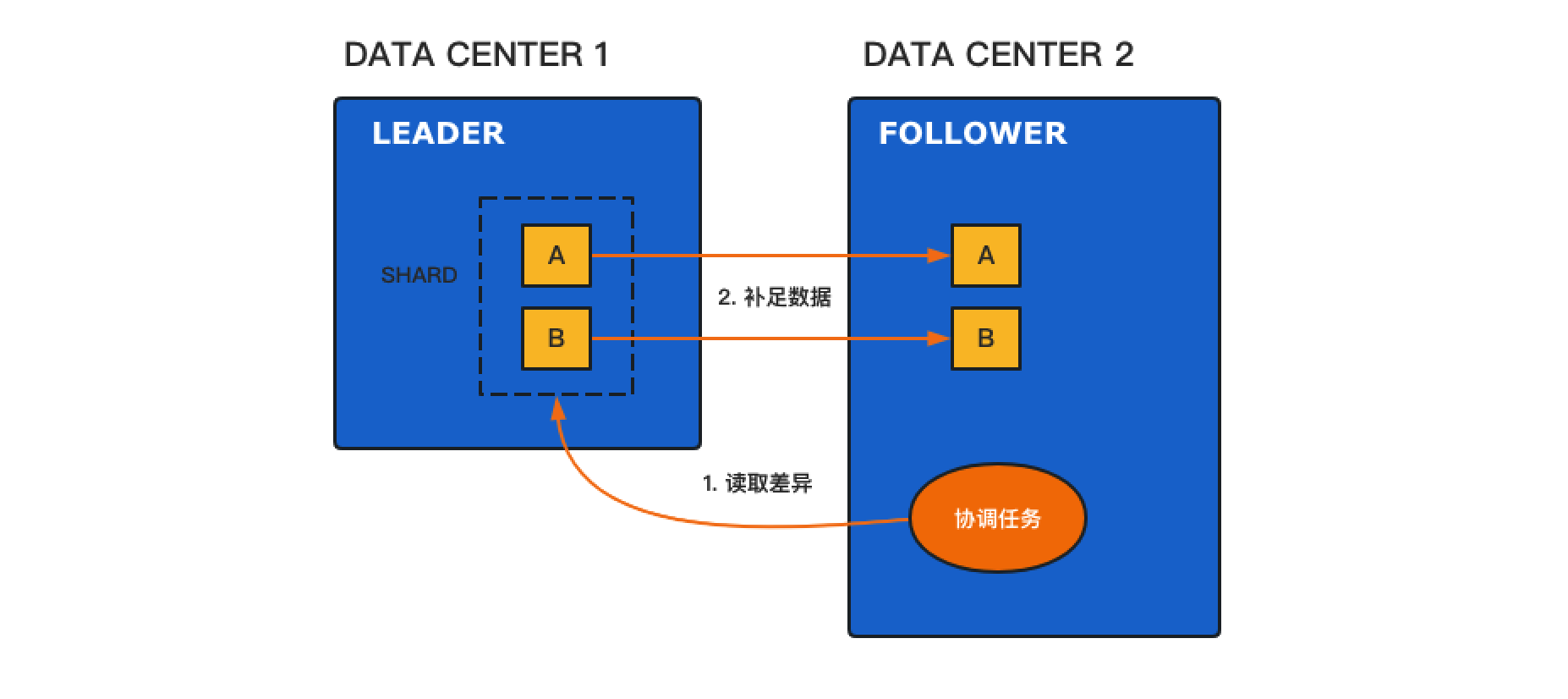
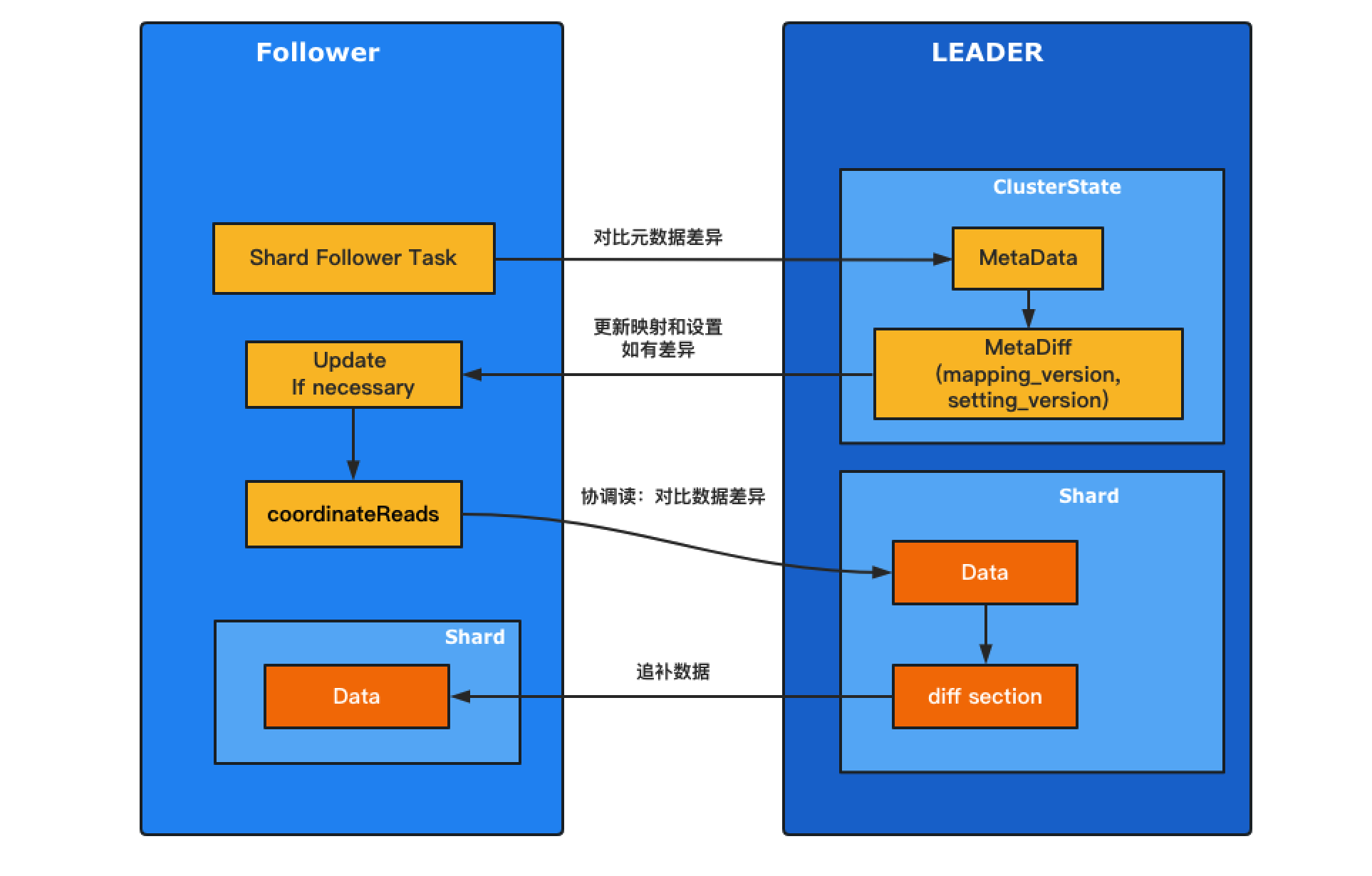
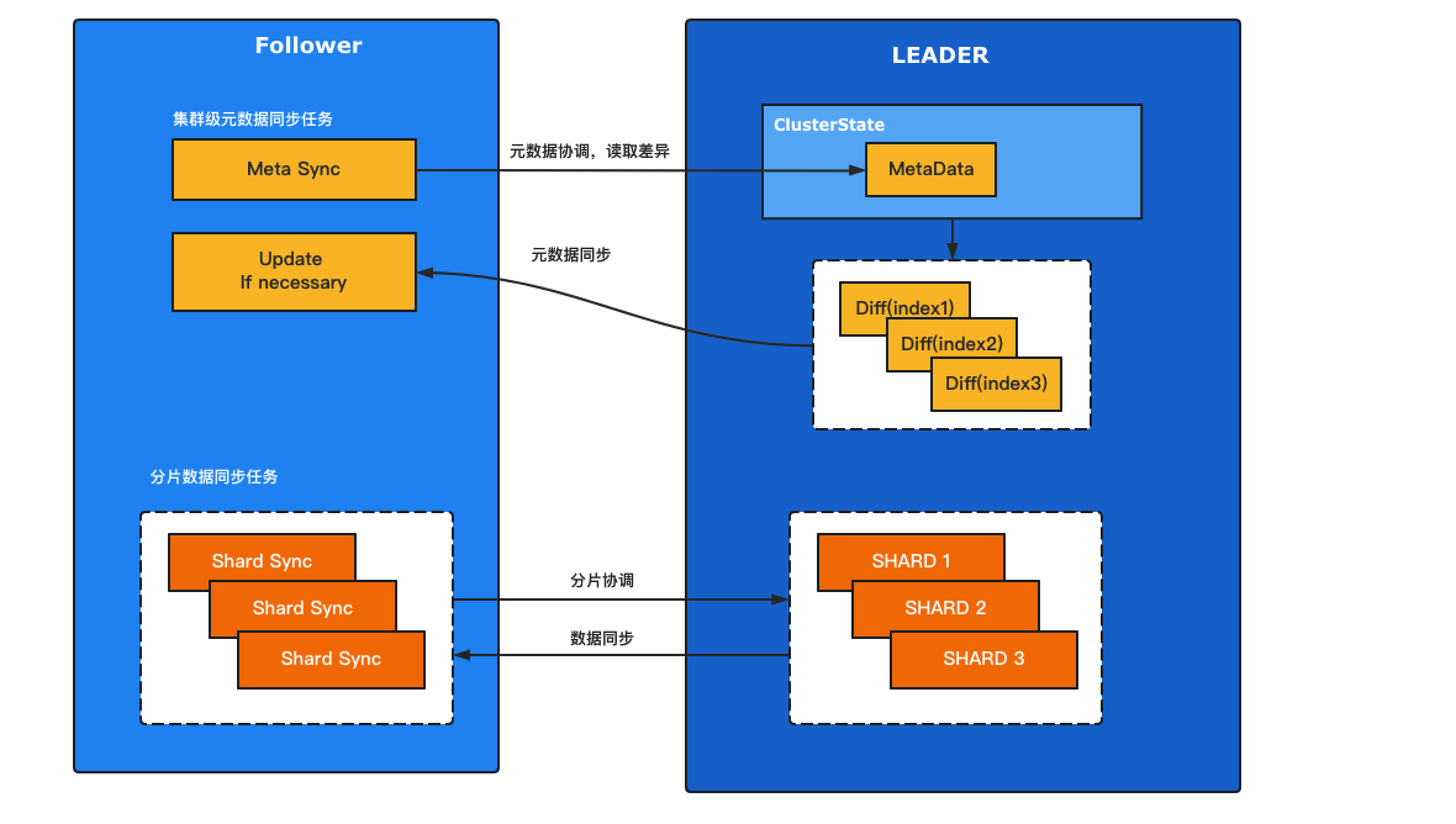
日志记录可以在开发和排查问题时提供重要线索。Elasticsearch 的日志功能非常强大,可以捕捉许多有用的信息,包括应用错误日志,接口执行耗时,网络连接状态等。在开发环境中启用日志可以提高调试效率,而在生产环境中启用日志可以帮助快速定位和解决问题。
日志场景特点
- 写入吞吐高:持续写入数据量大,呈线性增长趋势;
- 存储数据量大:日志数据需要保留较长的存储周期,通常每月存储量在上百个GB;
- 冷热特性明显:日志排查倾向访问近期数据,历史数据常用于使用评率较低的统计分析;
- 实时性查询:日志场景通常会作为应用服务的问题排查,或监控数据的大盘展示,因此查询延迟的实时性直接影响用户端的体验;
优化策略
1.按照日期规划索引
索引名设计为按天翻滚的策略 log-2023.06.01、 log-2023.06.02、 log-2023.06.03 ...
带来的好处:
- 如指定时段的日志分析,可通过前置过滤规避大量范围外的索引,提升检索效率。
- 利于索引的生命周期管理,定期迁移冷热存储层及删除过期索引。
2. 合理设计索引结构
通过索引模板,统一规范日志索引结构化数据。
- 字符串字段:ES默认的行为会将字符串字段转化为keyword + text的嵌套结构字段,造成索引量翻倍。 我们可以通过dynamic_templates将字符串类型数据默认转化为keyword类型。大文本字段依旧采用text,节省存储空间。
- 数值字段 : ES的数值类型(long、integer)在term关键词查询的效率远低于keyword类型。因此具备数值特性的字段如果不需要范围查找,建议统一设置为keyword类型。
- 压缩优化 : "codec": "best_compression" 启用压缩算法提高存储效率节省空间。
- 写入优化 :"refresh_interval": "60s" 每隔60s刷新数据可见性,提升写入效率。
template示例
POST _template/log-template
{
"order": 0,
"index_patterns": [
"log-*"
],
"settings": {
"index": {
"number_of_shards": "1",
"refresh_interval": "60s",
"codec": "best_compression"
}
},
"mappings": {
"_doc": {
"dynamic_templates": [
{
"strings_as_keyword": {
"mapping": {
"ignore_above": 1024,
"type": "keyword"
},
"match_mapping_type": "string"
}
}
],
"properties": {
"message": {
"type": "text"
},
"@timestamp": {
"type": "date"
}
}
}
},
"aliases": {}
}
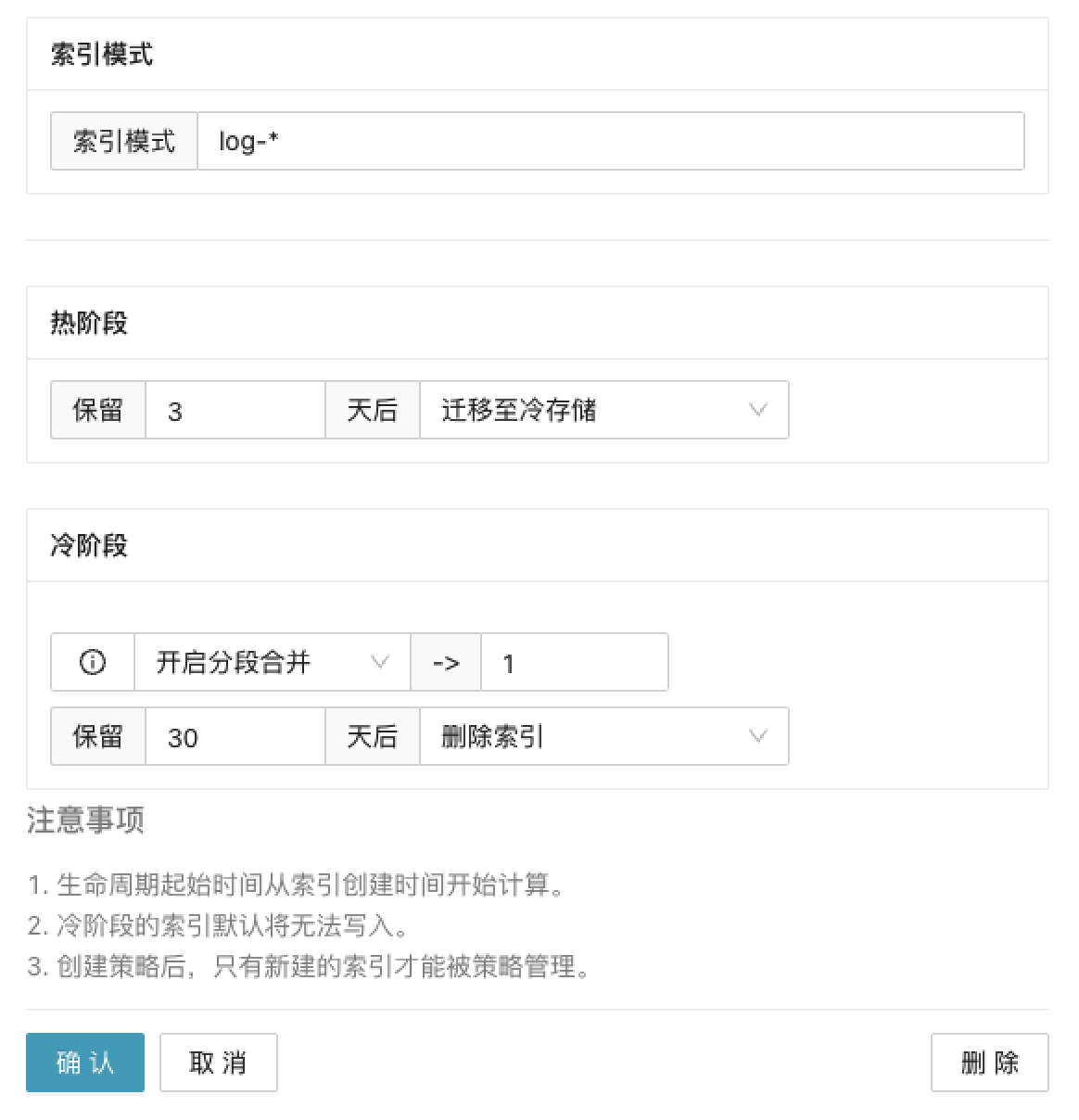
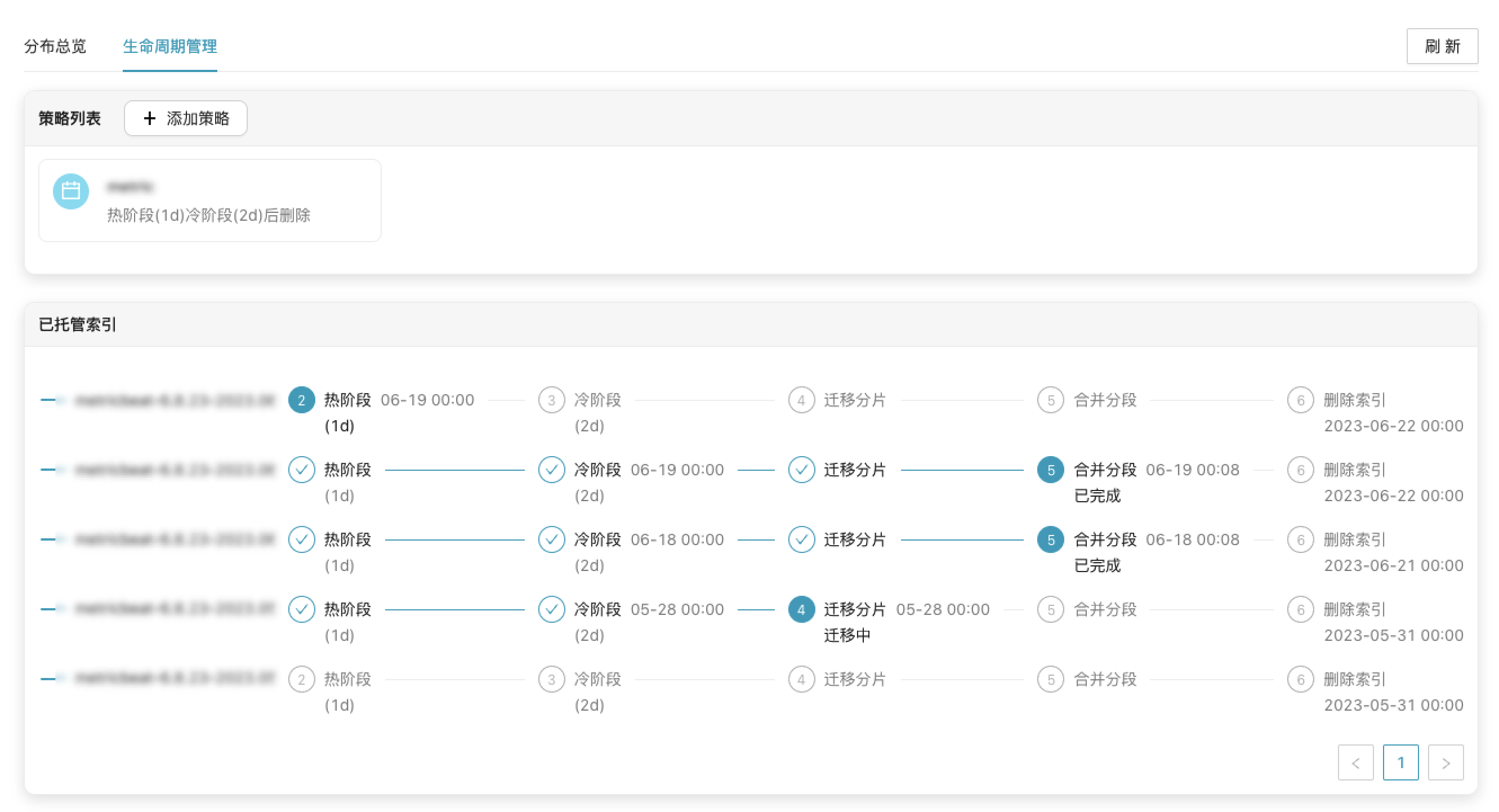
3. 设置索引生命周期
通过纳速云控制台-存储管理-生命周期管理,定期将日志索引数据进行冷热迁移并进行索引分段合并,降低存储成本。
tip
在纳速云平台冷存储相对热存储能节省近10倍的存储成本。
结语
综上所述,通过采取一些适当的日志场景优化措施,可以在保证日志记录准确性的前提下,减少日志的大小和数量,降低日志记录的成本和风险。