「 如无必要,勿增实体 」是极简主义者推崇的生活信条。摒弃多余的东西,简化繁琐的步骤,排除没必要的干扰,认清自己到底想要什么,最大限度把环境变得简单。 只有这样,我们才能在混乱而变化的环境下,拥有更多的时间和精力,找到值得珍视的东西,达到更加自由的生活状态,彻底实现「不为外物所累」。
起源篇「 写入Serverless 」
Nasu Elasticsearch Serverless 起源于多年前的一个想法,那时我负责阿里云ES的内核研发Leader,这个团队每年都有一个硬性KPI "引擎优化"。比如索引写入性能提升100%,存储成本降低100% ... 小伙伴们每天的工作就是研究引擎源码,看issue,分析行业的paper,尝试用一些前沿的算法改造引擎,尽管有一定的产出,但也伴随着极大的不确定性。闲暇的某天 我突然冒出一个想法,既然是云计算,那么多机器闲置着也是浪费,为什么不能在用户的集群旁边造个水池:将计算引过来,把结果返回去就好了,这样一来我只需要买些低配的机器,不仅计算大幅提升,成本还大幅降低,两年的KPI任务搞定 🧐 于是诞生了第一代「写入Serverless」即 AliyunES Indexing Service
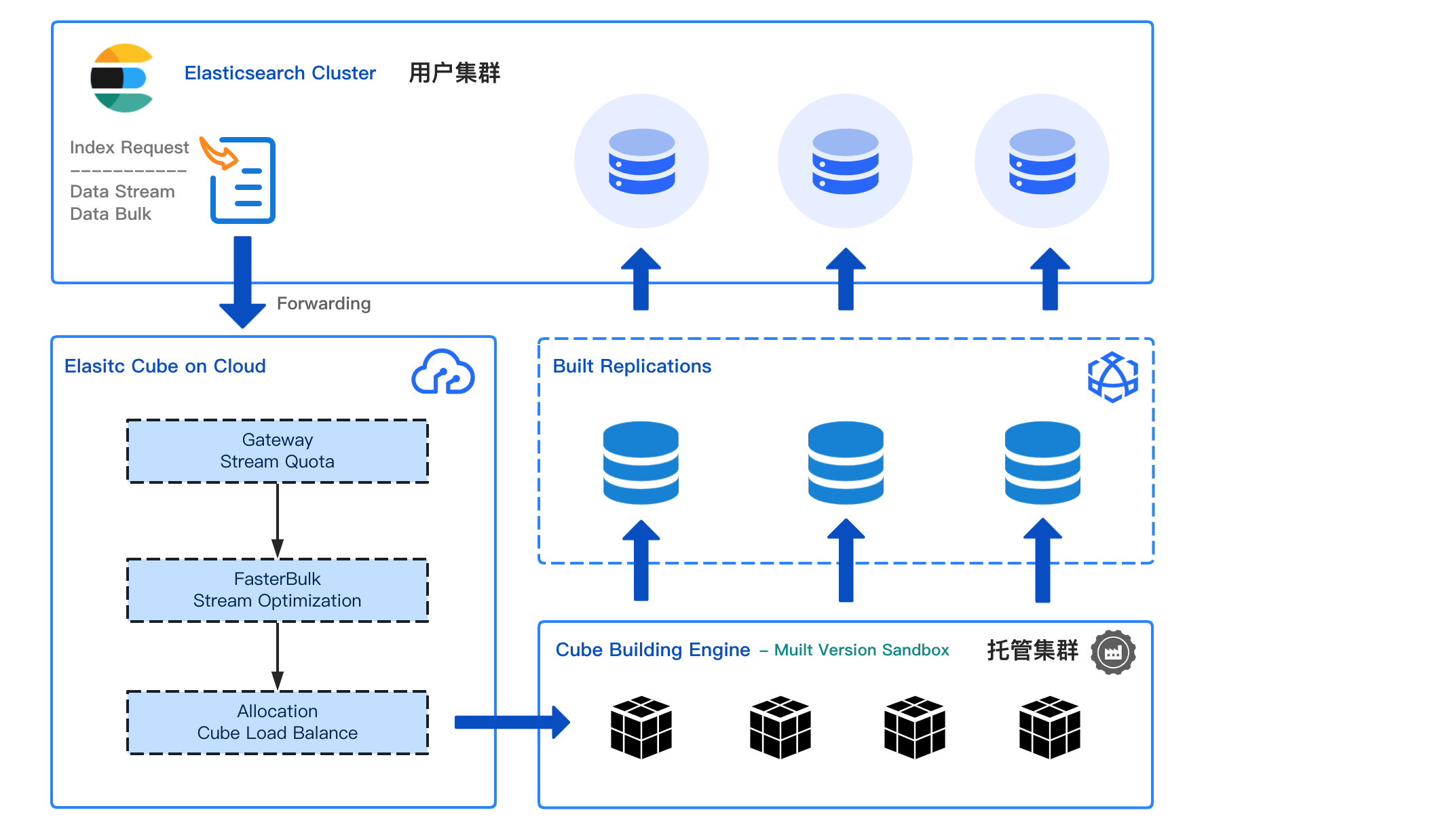
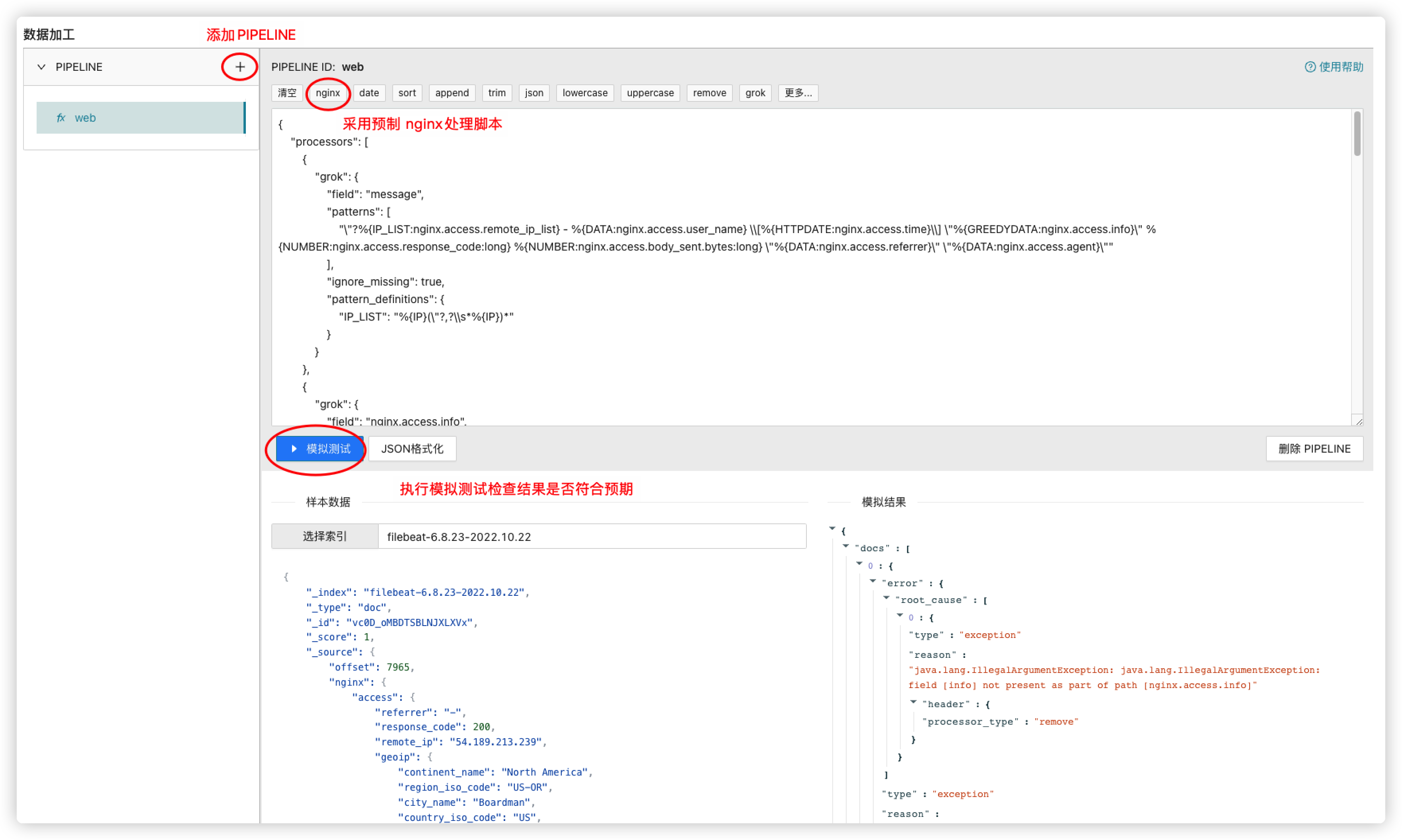
如上图,IndexingService的核心任务便是 帮你建索引。
- 用户侧的Bulk写入全部被转发到托管计算集群。
- 托管集群构建好完整的索引,通过物理复制写回到用户集群。
- 整个过程对用户是透明的,完全无感知是被托管了,只能感受速度上的极大提升。
达到的效果便是2核8GB的小集群可以达到20万写入QPS,提升了准10倍。这项技术上线后的成果也是不错的,很多头部客户如小红书、米哈游、康众、蜻蜓、罗辑思维、货达纷纷用了起来,反馈也很不错。
但是随着用户的使用深入,我们发现写入Serverless只能满足部分场景,由于用户集群规格降低了 导致查询速度太慢,于是又有大量客户退回到原始的高配置集群。 如何解决查询的托管成了接下来需要思考的重点。
进化篇「 ZSearch 」
接下来的一段时间 我担任阿里巴巴及蚂蚁集团Elasticsearch开源委员会的第一任PMC,这个组织汇聚所有阿里的ES爱好者,以中立的视角和态度将研发成果反哺到所有事业部。蚂蚁集团由于当时没有独立的搜索事业部,技术呈烟囱式发展,各个业务部门是有什么用什么,solr、海狗、Elasticsearch、HA3 百花齐放,由于没有统一的技术栈,从方案讨论、项目实施,稳定性保障、后期维护给每个团队都带来了极高的成本, 于是「 统一搜索中台 」呼之欲出。
结合之前的经验,平台应该怎么设计,“用户怎么用才能达到最爽的状态” 我带着这些思考开始了新一代的搜索平台设计。
我们真的需要给用户一个集群吗?

经过重新设计的产品被命名为 ZSearch ,这是一款面向数据的搜索服务,而非集群的托管平台,设计目标便是极简化用户的体验,只暴露一个API网关,百分百兼容Elasticsearch接口,屏蔽底层所有的一切。
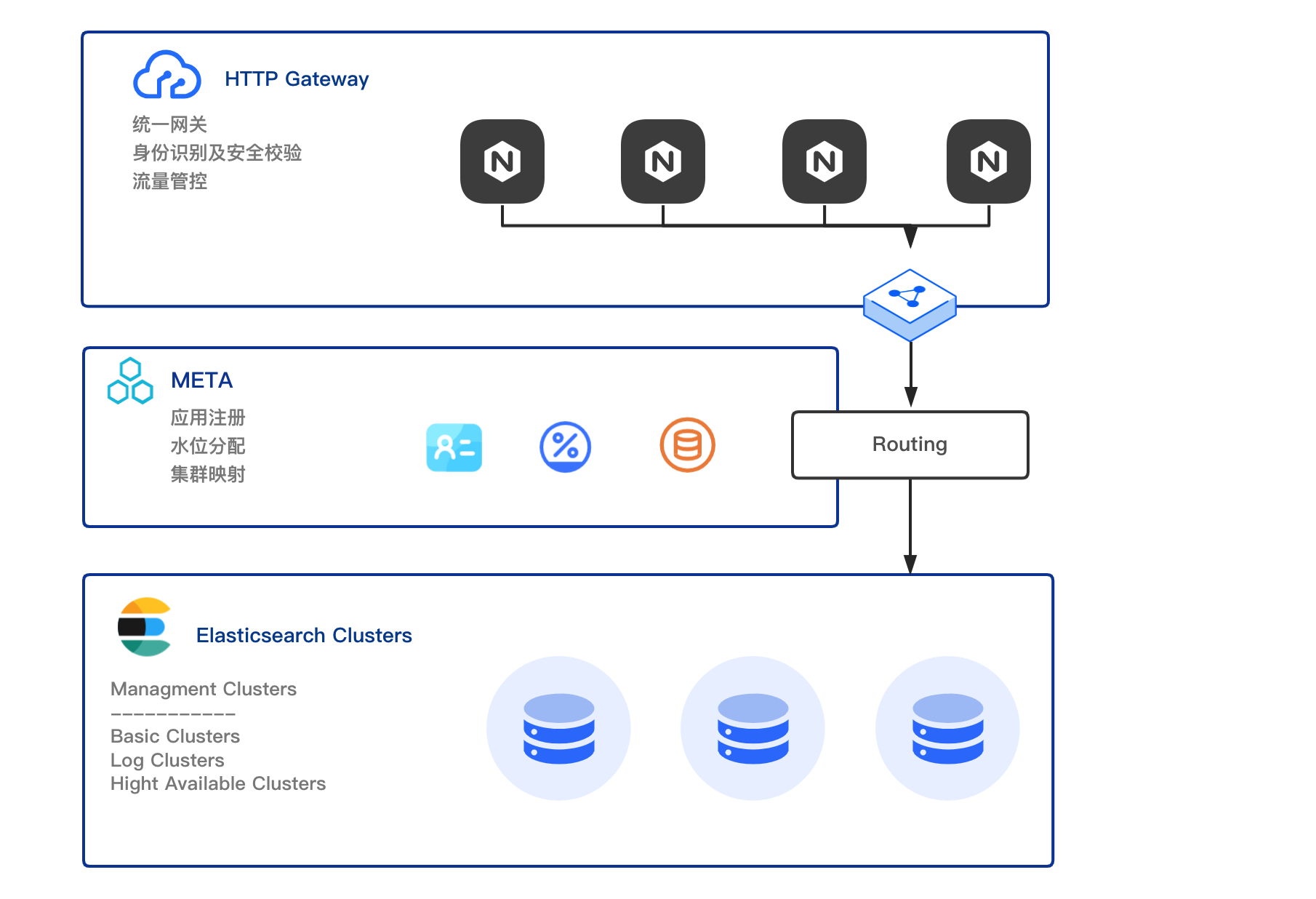
上图便是ZSearch的核心架构,API Gateway 作为统一接口层,负责所有用户层的接口调用。Meta 作为元数据中心,用于对接ES的集群注册和用户集群的分配。底层的 Elasticsearch 真实集群被规划为海量、计算、通用三种类型,用于承载不同业务的真实载体。
ZSearch的上线,将业务从运维中解放出来,也从架构层面统一了基础设施。推出后反响强烈,从支付宝C端、财富、借呗、花呗等20+核心链路到数百个长尾应用,一路成长为如今的蚂蚁集团搜索中台,同时金融场景下对稳定性的变态要求,也反向推进了ZSearch的技术打磨,衍生出XDCR、PackingPool等核心技术。
由于使用极为简单,在未经任何推广的情况下 ZSearch的业务也延伸到到阿里集团的各个事业部,例如菜鸟、天猫、淘宝、阿里云、高德等40多个BU。从天猫精灵、语雀、机器学习PAI 到菜鸟海关、芝麻征信、优酷短视频...处处都能看到ZSearch的影子。
重生篇「 Nasu Elasticsearch Serverless 」
随着ZSearch业务的逐步稳定,一个新的想法时常萦绕在心头,能不能让他走出去,服务全国的广大用户呢。
如今,在疫情导致的经济持续下滑的严峻背景下,如何为广大企业推出一个款使用简单、经济实惠、成熟稳定的搜索解决方案,成为我下个阶段的主旋律。说干就干,2022年我从大厂走了出来,为这个想法付诸自己的行动。
成立纳速云科技有限公司,经过数月的闭关,新一代的面向全国用户的在线搜索产品诞生了 - Nasu Elasticsearch Serverless (NES)
为追求更极致的用户体验,NES在设计之初相比ZSearch提出了更高的要求:
- 无需预设业务场景,做到真正的自助接入。
- 面向跨云设计,实现更高要求的容灾体系。
- 从租户隔离提升到计算隔离,实现更高的可靠性。
- 建立对用户透明的集群迁移机制,实现全自动化的服务自治。
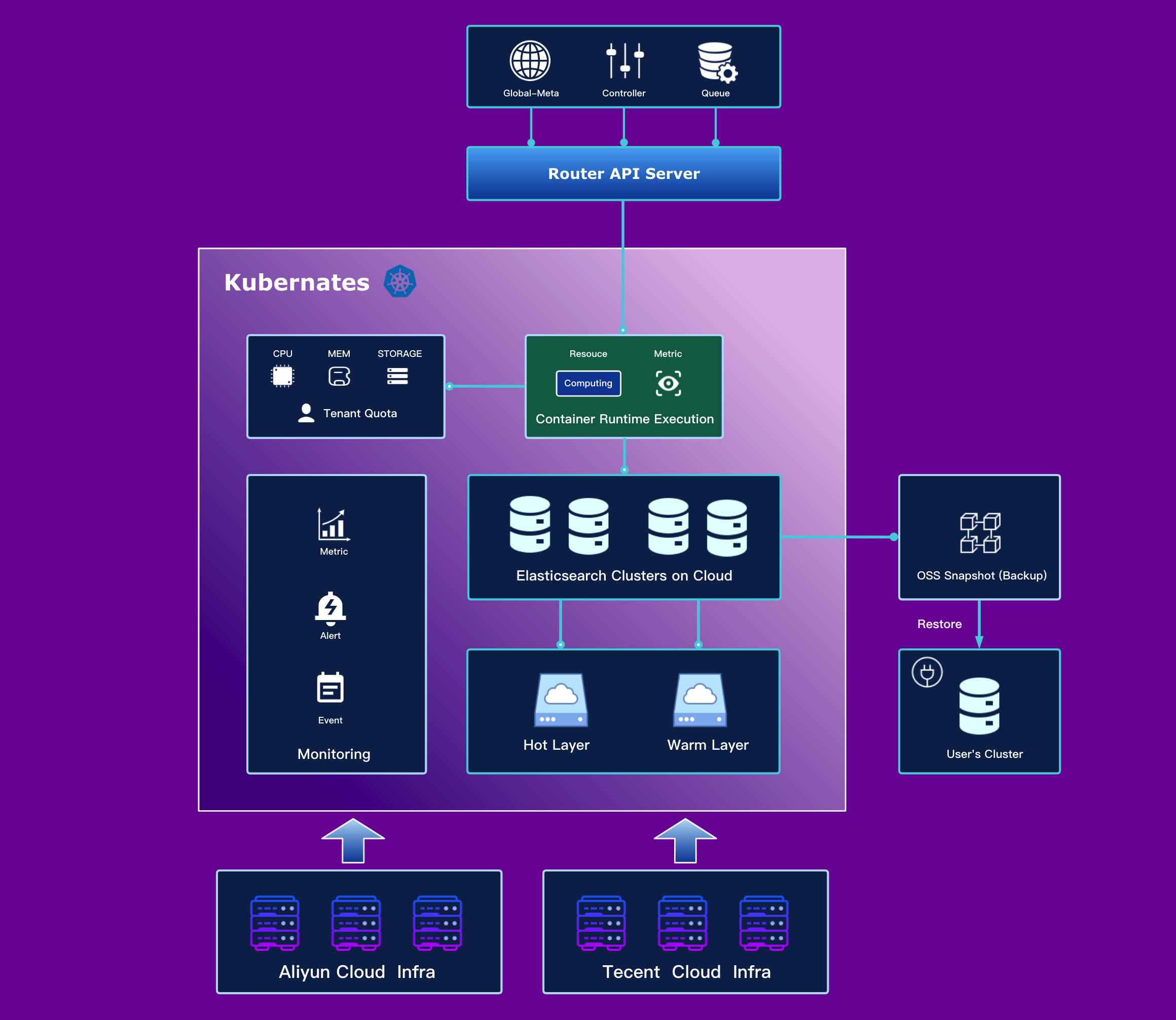
如上图,Nasu Elasticsearch Serverless 从以前的 sigma 底座迁移到云原生的Kubernates,利用其跨云特性打造更为标准化的容灾体系;利用容器化、存储架构分离、高速网络、智能熔断等技术构建更为灵活的多租户集群体系;建设全局监控、主动报警、事件回溯提升整体服务的可观测性。 通过各个核心能力的提升,将之前的搜索中台提升到商业级的可信服务。
目前我们没有销售,但上线仅数月 Nasu Elasticsearch Serverless 已接入上百个应用,每天接收上万个设备的数据上报,许多用户都是在没任何交流的情况下直接开通企业版 😅。
信任是可贵的,客户将后背无条件的交付给我们,作为后端的我们 目标也只有一个:为你打造一个最为可靠的API。接下来 纳速云的重点依然是投入在稳定性建设上,将可靠性做到业界最强是我们当前的唯一使命。