
纳速云 XDCR(Cross DataCenter Replication)
XDCR 跨集群复制通常用于以下场景:
- 异地高可用 (HA):对于许多核心链路应用程序,都需要能够承受住数据中心或区域服务中断的影响。通过 XDCR 中的原生功能即可满足跨数据中心的 DR/HA 要求,且无需其他技术。
- 就近访问:将数据复制到更靠近用户或应用程序服务器的位置,可以减少延迟,降低成本。例如,可以将产品列表或参考数据集复制到全球 20 个或更多数据中心,最大限度地缩短数据与应用程序服务器之间的距离。
ES的跨中心高可用也可以通过第三方技术来解决,例如双队列复制、网关流量双通道分发,但这种做法很繁琐,会带来大量的管理开销,而且有很大的数据一致性缺陷。通过将跨集群复制原生集成到 Elasticsearch 中,我们让用户摆脱了管理复杂解决方案的负担和缺点,并能提供现有解决方案所不具备的优势。
CCR vs XDCR
Elastic 官方的 CCR (cross-clusterreplication)也提供了类似的功能,CCR 属于xpack增强包中的功能,需要白金级、企业级证书才可使用。而XDCR 诞生于蚂蚁金服,由城破带领的搜索内核团队打造,该方案实际上比社区的 CCR 早半年落地,通过不断的踩坑和优化,最终满足了金融场景下对数据可用性和容灾能力极为严苛的要求。
本文从原理及设计层面阐述两者的不同之处。
顶层设计
面向分布式系统,一款优秀的高可用方案从顶层设计层面要抓住以下几点:
- 面向错误设计
分布式环境的复杂性往往会遇到不可预期的异常,如网络错误、格式冲突、节点hang住、异常流量、用户操作打断等等。设计层面要充分考虑这些因素,当异常发生时做到:
- 核心服务解耦:主备集群相互无干扰。
- 无状态化:复制任务保证原子性和无状态,任务之间无关联,失败后可重试。
- 无干预:异常恢复时,任务可自动调度恢复,无需人为介入。
- 数据一致性
任何情况下,即便是数据丢失也比错误的数据可接受。
- 采用更简单的单主模式,放弃双AA。
- 始终通过
operation_log恢复,保证数据一致性。 - 垃圾数据可丢弃、可强制覆盖。
- 可扩展性
从平台层面,面向不可预期的业务数据增长:
- 复杂度可控:不会随着索引的增加导致任务的指数级增加。
- 资源可控:计算资源始终控制在合理的资源池内。
- 可观测性
通过接口暴露底层任务状态,通过外围工具辅助监控报警,做到第一时间能发现现场:
- 任务实时状态
- 计算消耗状态
设计架构
CCR和XDCR都是采用拉模式(Pull Mode):即备集群创建协调任务,主动从主集群拉取数据差异并写回备集群 :
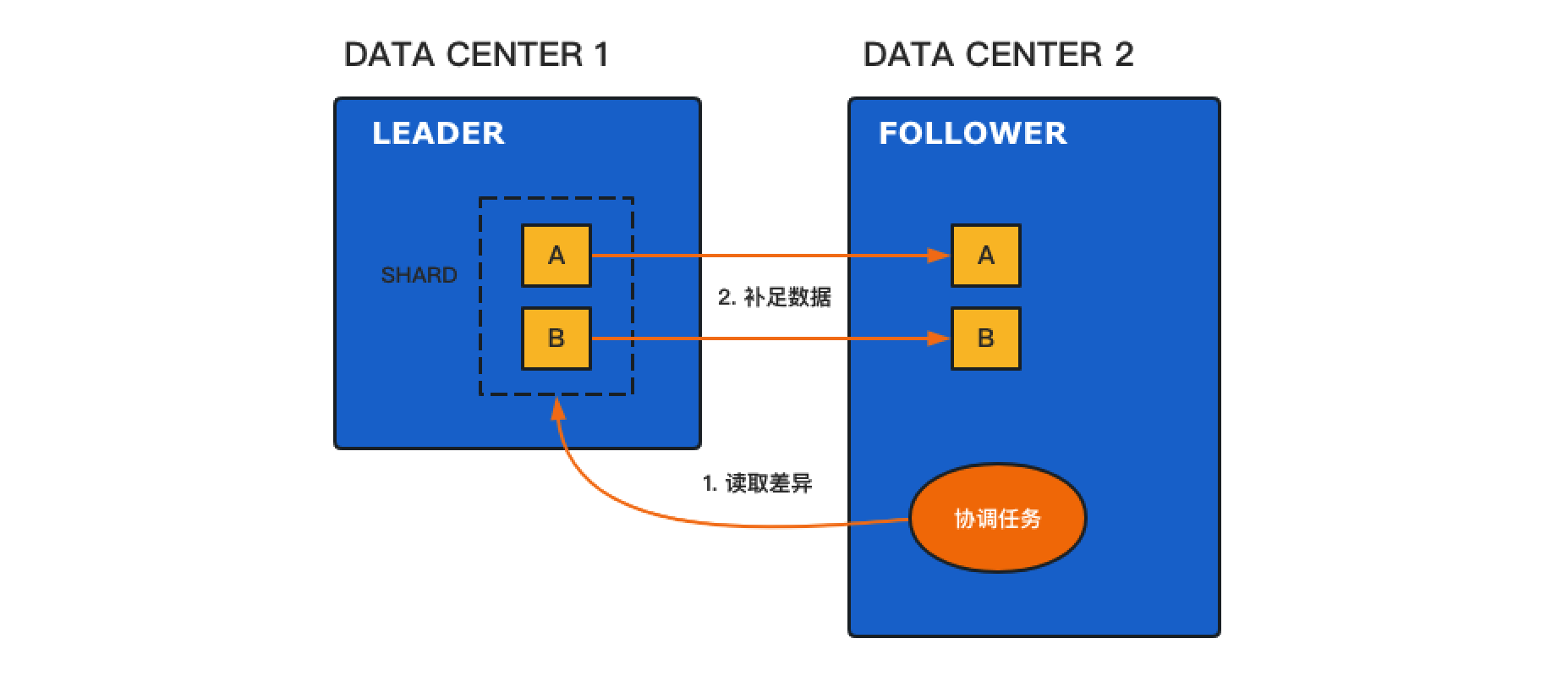
拉模式相对于推模式的方案更为简洁:
- 主集群处理逻辑简单,只需要控制好拉请求的资源保护即可。
- 备集群通过任务的无状态化设计,保障断点续传的可靠性即可。
实现层面差异
CCR
核心任务处理逻辑
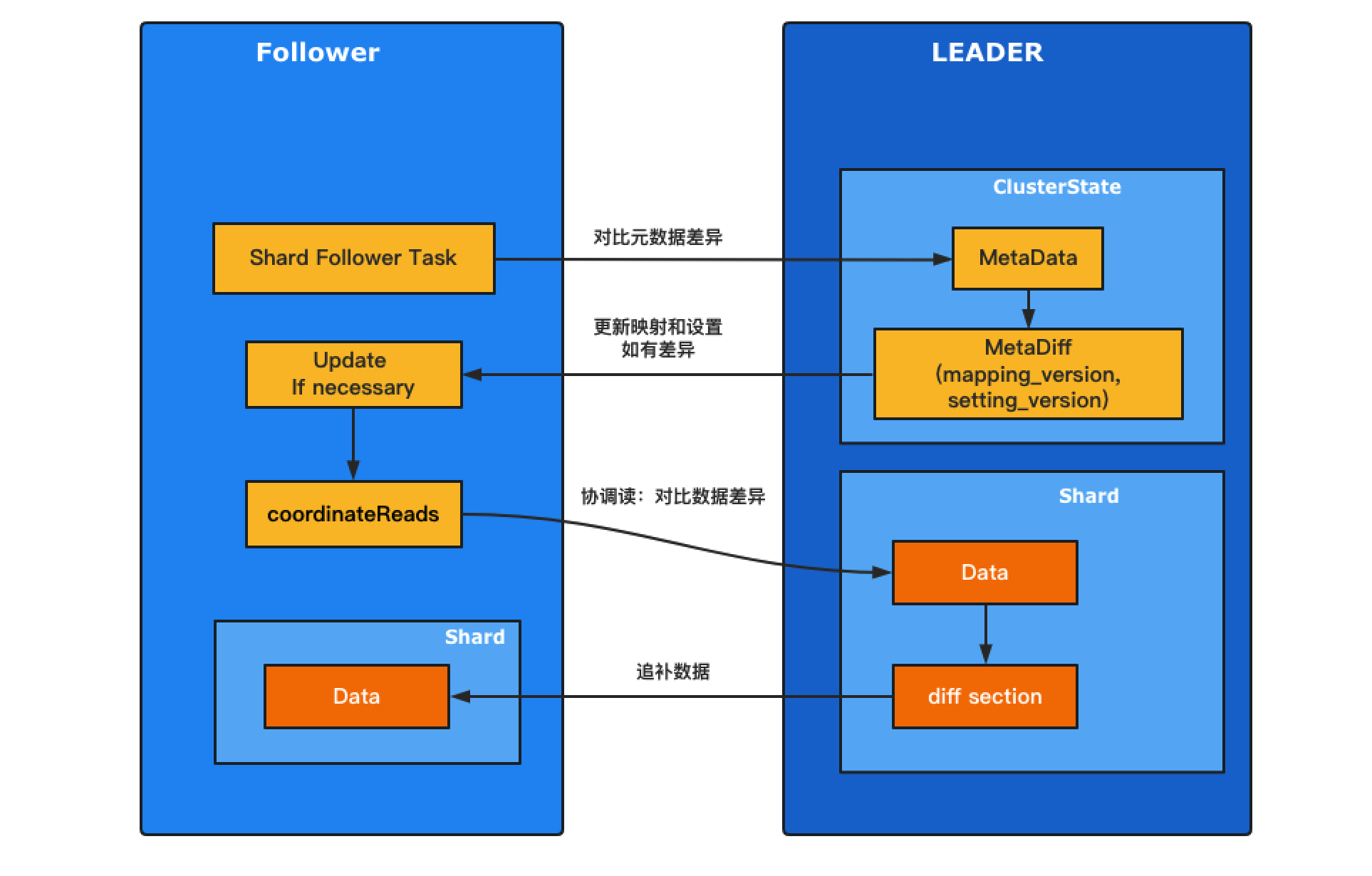
代码片段
void start(...) {
...
// 更新备集群mapping,提供了Leader的mapping version,并确保相同。
updateMapping(0L, leaderMappingVersion -> {
synchronized (ShardFollowNodeTask.this) {
currentMappingVersion = Math.max(currentMappingVersion, leaderMappingVersion);
}
updateSettings(leaderSettingsVersion -> {
synchronized (ShardFollowNodeTask.this) {
currentSettingsVersion = Math.max(currentSettingsVersion, leaderSettingsVersion);
}
// 协调读,取出数据差异进行复制。
coordinateReads();
});
});
}
CCR跨集群复制,将元数据同步和数据同步串联在主链路上,在分片数量不多的情况下能稳定的运行,但试想下如果是平台级的集群级同步,有成千上万个shard同步任务并行运行时,读取master的集群状态开销就不可小视了。
XDCR
XDCR从架构层面将元数据同步和Shard数据同步进行了分拆,如下图所示:
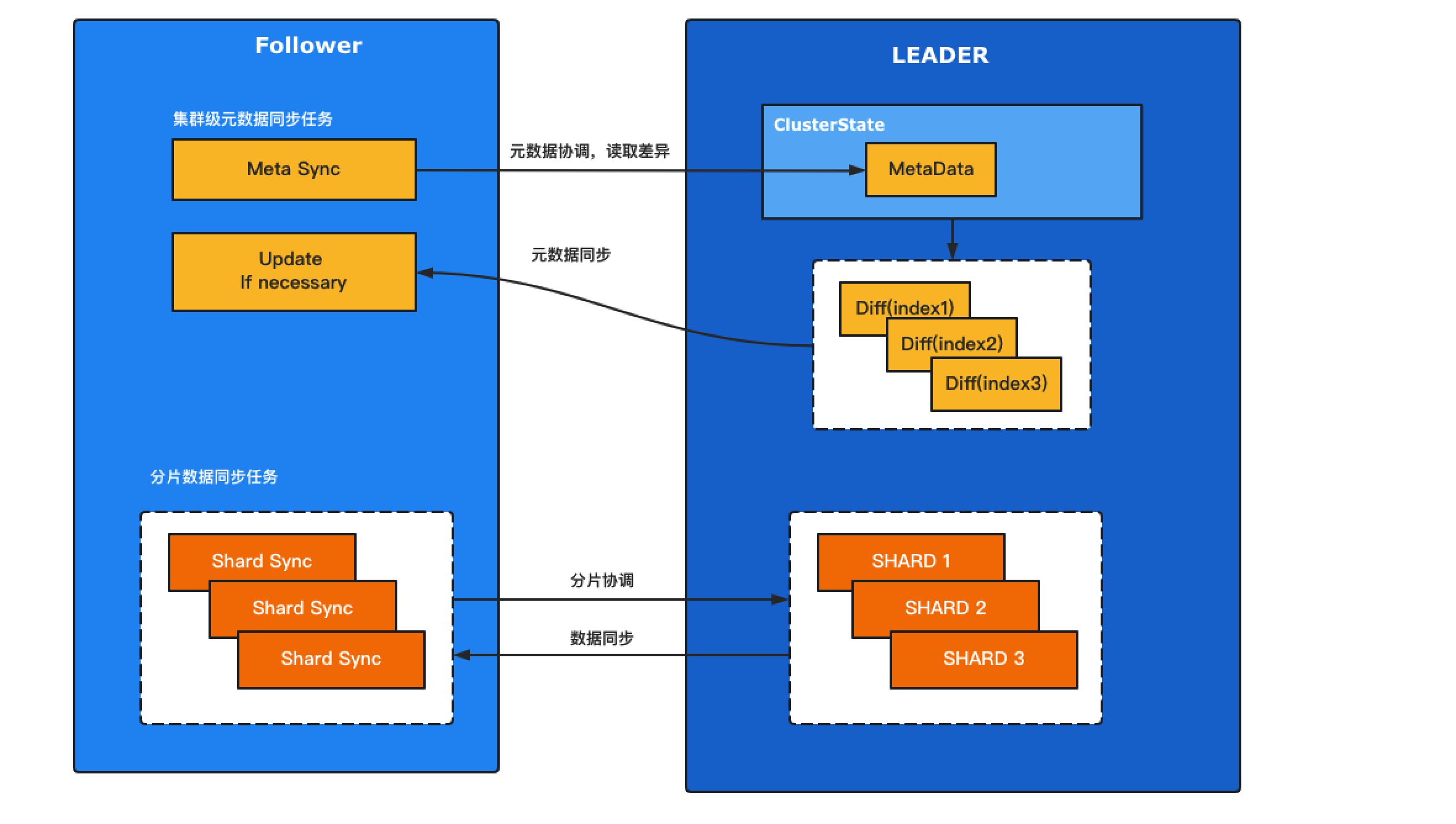
核心差异
- 备集群始终只维护一个全局的元数据同步任务,用于同步所有已注册同步的索引mapping和setting。
- 分片同步只处理数据同步,如遇到mapping,setting不一致则抛出异常,通过不断重试等待元数据同步后恢复。
从现象上来看,当主集群的索引mapping或setting更新时,XDCR相对CCR会停顿几秒 然后跟上。但带来的好处是:
- 在大规模的同步场景下,集群的master压力直线下降,且不会随着分片的增长而增加。
- 分片复制任务更为精简,功能原子性更强,更易于后期的架构演变。
本文阐述了两者的核心差异,当然还有更多的细节差异,如有兴趣的同学可以阅读XDCR源码分析。