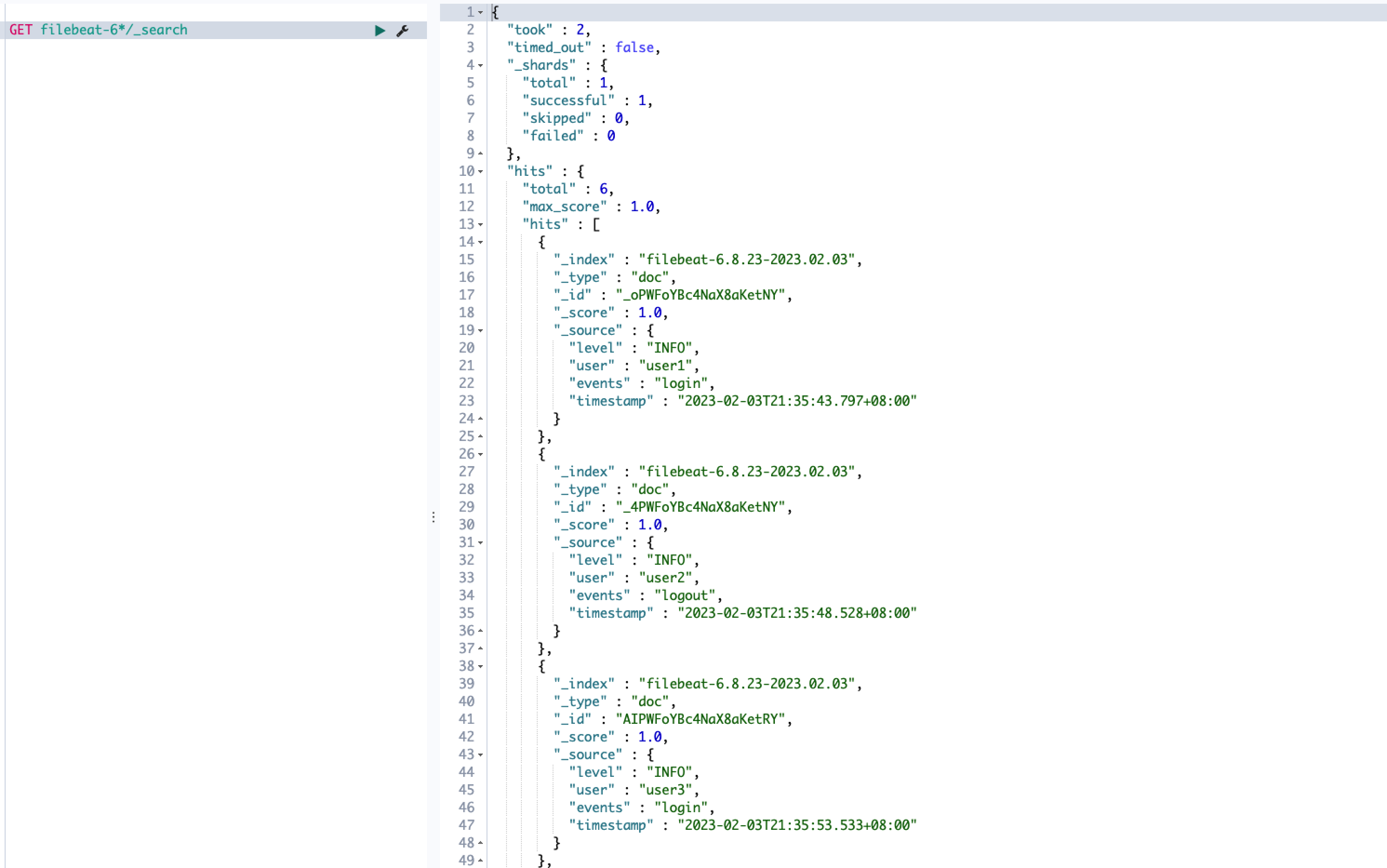
数据加工
数据加工允许您在索引之前对原始数据执行结构化的转换,例如删除某些字段、从文本中提取值和丰富数据。 最常见的场景如 filebeat、 metricbeat 采集器上报的原始日志转换为真实的结构化索引数据。

概念
- 采集器(agent) 例如 metricbeat、filebeat、healthbeat 等部署在服务器上的agent,用于采集日志文件、系统状态等信息。
- 处理器(processor) 数据处理算子,例如 rename 重命名字段,drop 删除字段。
- 管道(pipeline) 数据处理管道,由一系列处理器组成。每个处理器按顺序运行,对传入的文档进行特定更改。
传统方式的痛点
使用 ELK 处理数据加工常常会耗费大量的时间精力,最常见的痛点:
- 看不到采集结果: 配置了数据采集器,但ES端一直看不到数据。
- Pipeline 调试难:官方Kibana的
grok debugger仅仅提供文本的模式化调试,但实际使用时往往更需要对pipeline的整体调试。 - 联调链路长:真实数据往往复杂,需要不断修改 pipeline ,由于没有所见即所得的结果,只能通过不断试错来推进。
高效的数据处理方式
针对以上痛点,纳速云针对数据加工流程做了大量优化,可采用以下更为高效的处理方式:
第1步 简化采集器配置,确保数据正确的上报。
采集端不做任何pipeline配置,以最精简的方式运行,先确保发送端的正确性。例如filebeat采集日志,此时原始文本通常打包存储在索引的 message 字段
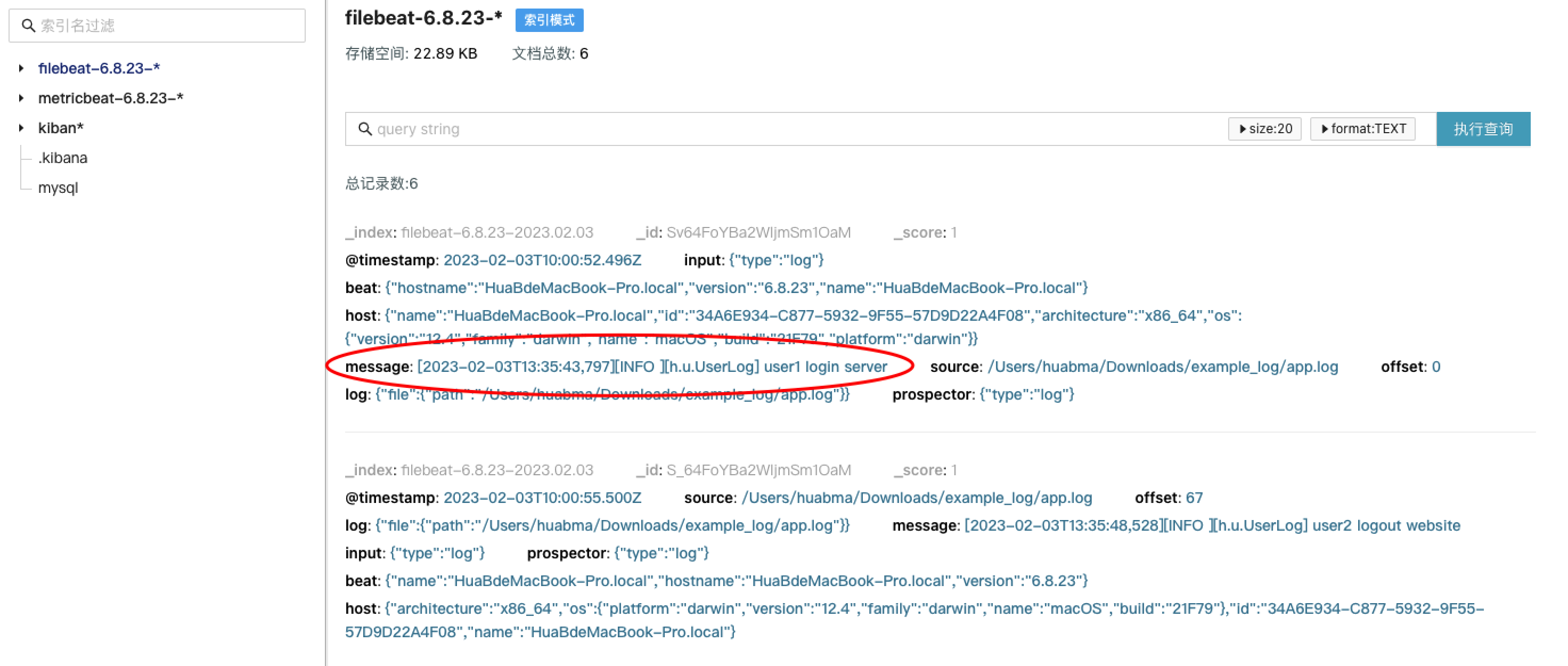
第2步 PIPELINE 在线调试
进入「应用管理」-「数据处理」
选择真实的数据样本,模拟调试pipeline的运行结果,直至满足预期。
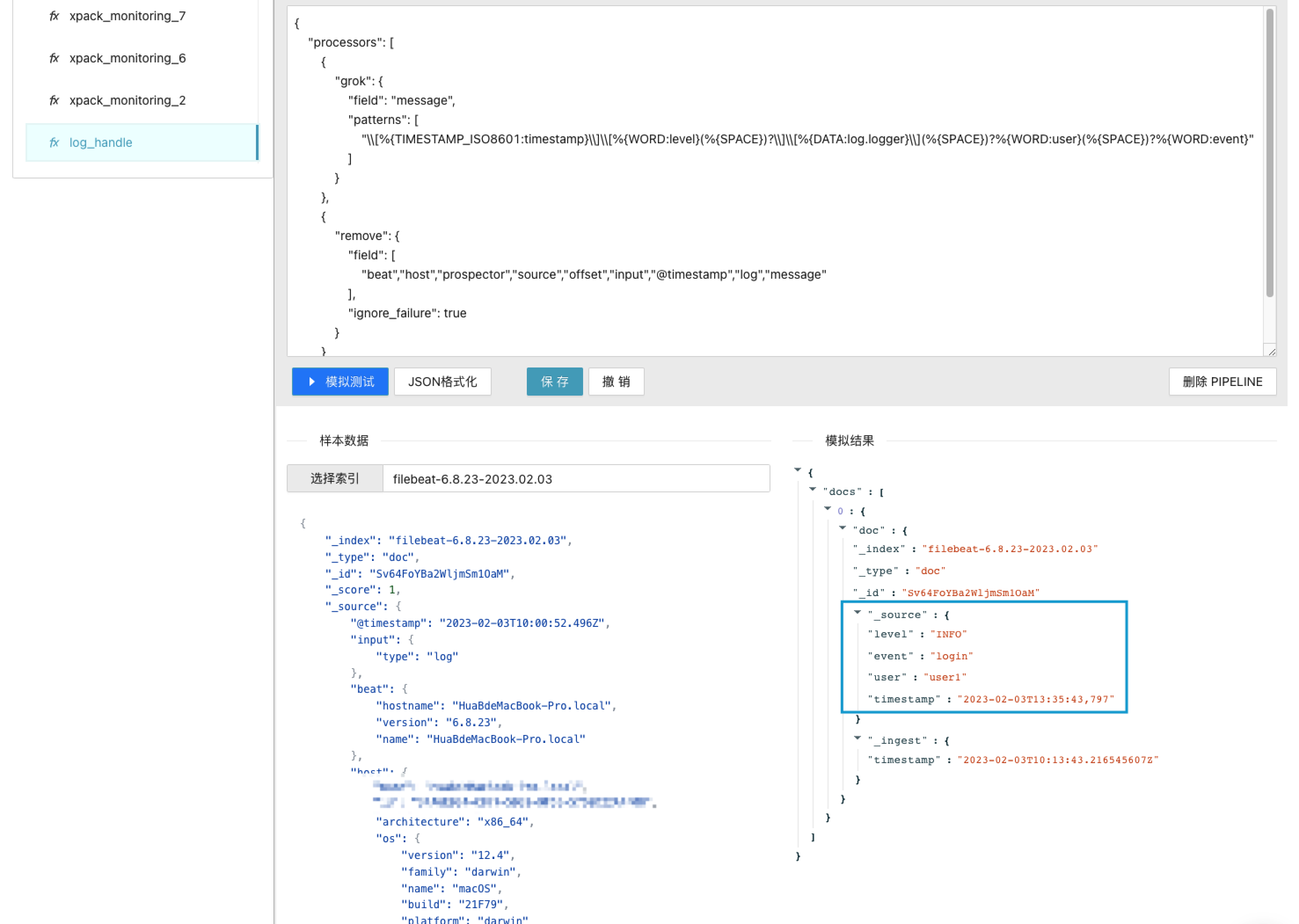
第3步 为采集器配置Pipeline
为采集器配置pipeline
output.elasticsearch:
hosts: ["router.nasuyun.com:9200"]
protocol: "https"
username: xxx
password: xxx
pipeline: log_handle
- 清除旧的数据 删除已导入的ES索引,删除beat目录下的data目录(位点)。
- 重启beat 新导入的索引数据为处理过后的结构化数据。