性能优化
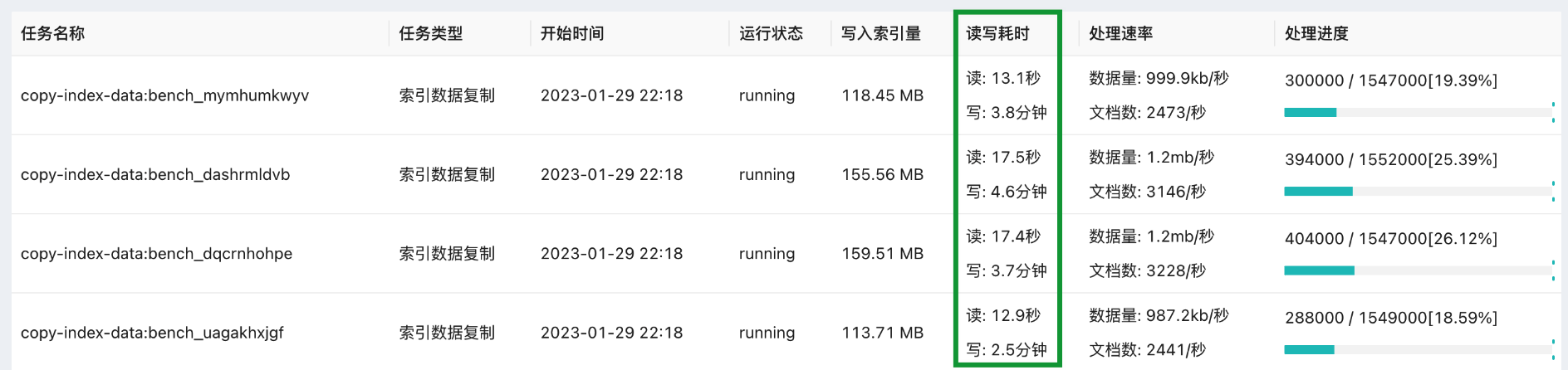
nasu copy 采用读写双工模式,即数据抓取和数据写入分别在独立的线程池内完成,互不影响。 通常我们可以利用任务状态的读写耗时判断瓶颈所在,合理调配资源以提升整体性能。
info
nasu-copy 已做了大量的默认配置优化,用户自行配置有可能造成性能的下降,只需根据实际业务场景做适当的调整。
策略1. JVM优化
- 堆内存大小 如您的迁移服务器资源充沛,可适当提高运行的堆内存分配,编辑 nasu-copy ,默认使用1Gb堆内存大小,通过以下配置调整堆内存大小:
JAVA_OPTS="-Xms1g -Xmx1g" - 垃圾回收策略 使用JDK11或以上的版本,使用G1垃圾回收策略。
策略2. 读写任务调优
编辑 copy.yaml
# 索引写入并发数
bulk.index_concurrency: 4
# 索引写入线程池大小
bulk.thread_pool_size: 8
# 每秒查询请求数限制
read.requests_per_second: 100000
# 单批次查询抓取文档数
read.scroll_batch_length: 1000
# 读取缓冲区大小
read.buffer_max_bytes: 80mb
# 读取限流等待时间
read.wait.millis: 3000
关键配置
- read.scroll_batch_length:单批次查询抓取文档数,控制在一个请求批次的数据总量在 5~10MB 为最佳。
- bulk.thread_pool_size:索引写入线程池大小,配置为CPU核数的4倍为最佳。
其他配置
read.buffer_max_bytes 和 read.wait.millis: 当源集群读取速度大于目标集群写入速度时,读取缓冲区会逐步增加,当到达
read.buffer_max_bytes指定的最大阈值时会触发读任务等待read.wait.millis毫秒。如果您的服务器内存充沛可适当调高,最高控制在1G以内。read.requests_per_second 每秒查询请求数限制,用于源集群的读取限速,当服务器配置过低时可调低该配置,用来保证拷贝任务的完整运行。
bulk.index_concurrency: 索引写入并发数,当设置为1时,索引将一个跟着一个拷贝到目标集群。