词库管理
中文分词,即 Chinese Word Segmentation,即将一个汉字序列进行切分,得到一个个单独的词。分词效果的好坏对信息检索、实验结果有比较大的影响影响。目前 Nasu Elasticsearch Serverless 集成了流行的开源IK分词器及拼音插件,方便大家使用。
GITHUB
基础分词测试
PUT /my-index
{
"mappings": {
"_doc": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}
POST /my-index/_doc
{
"content": "美国留给伊拉克的是个烂摊子吗"
}
POST /my-index/_doc
{
"content": "公安部:各地校车将享最高路权"
}
POST /my-index/_doc
{
"content": "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
}
POST /my-index/_doc
{
"content": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
POST /my-index/_search
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
词库管理
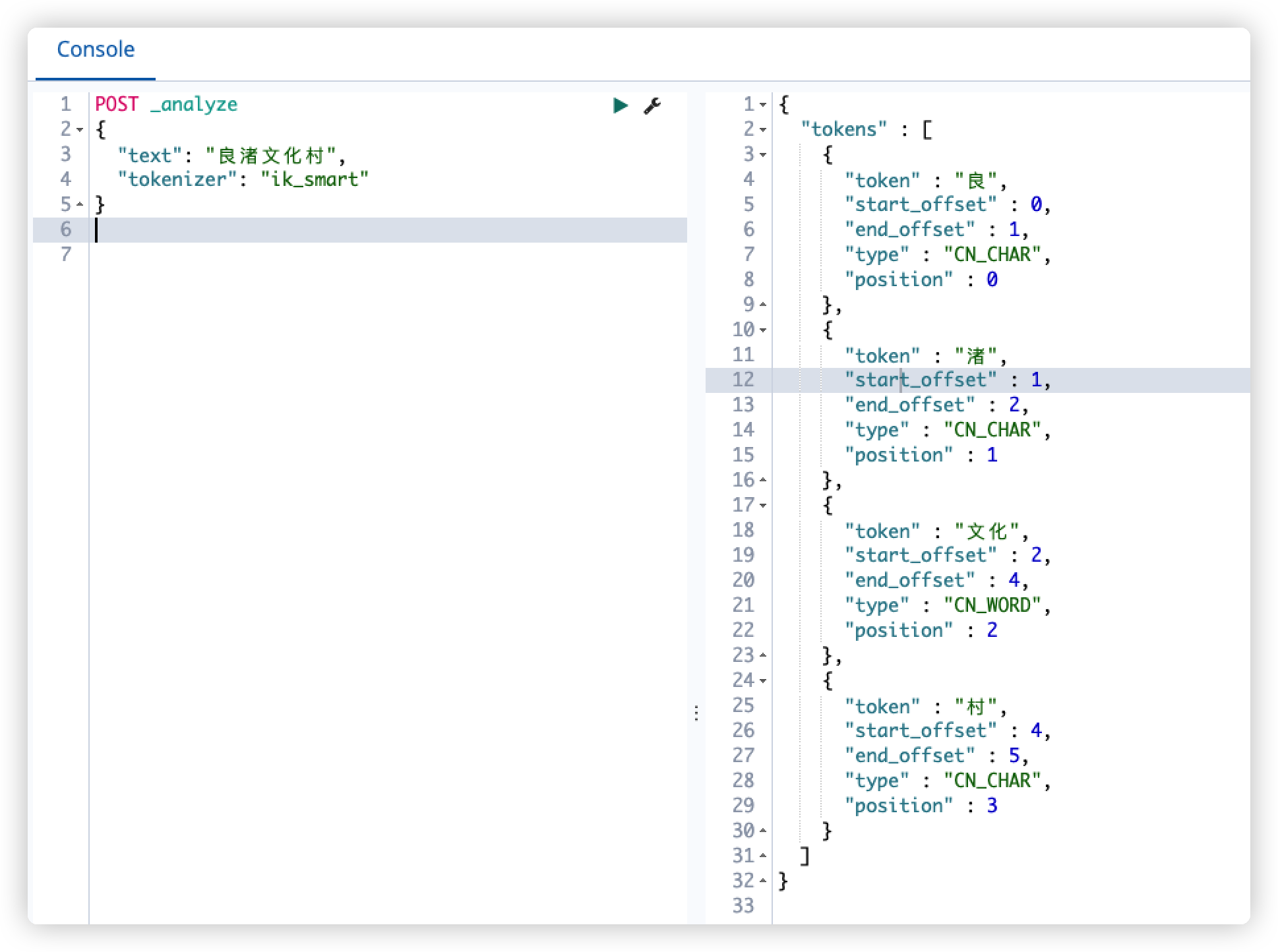
利用analyze分词调试功能
POST _analyze
{
"text": "良渚文化村",
"tokenizer": "ik_smart"
}
如无法识别的词语默认按单字切分
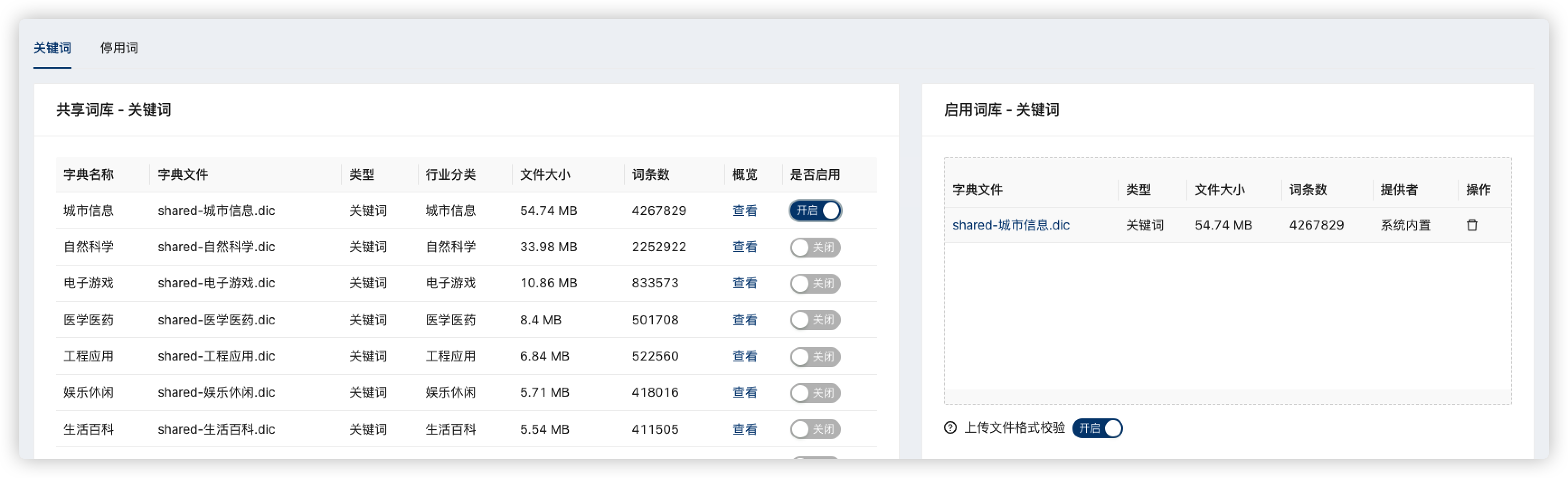
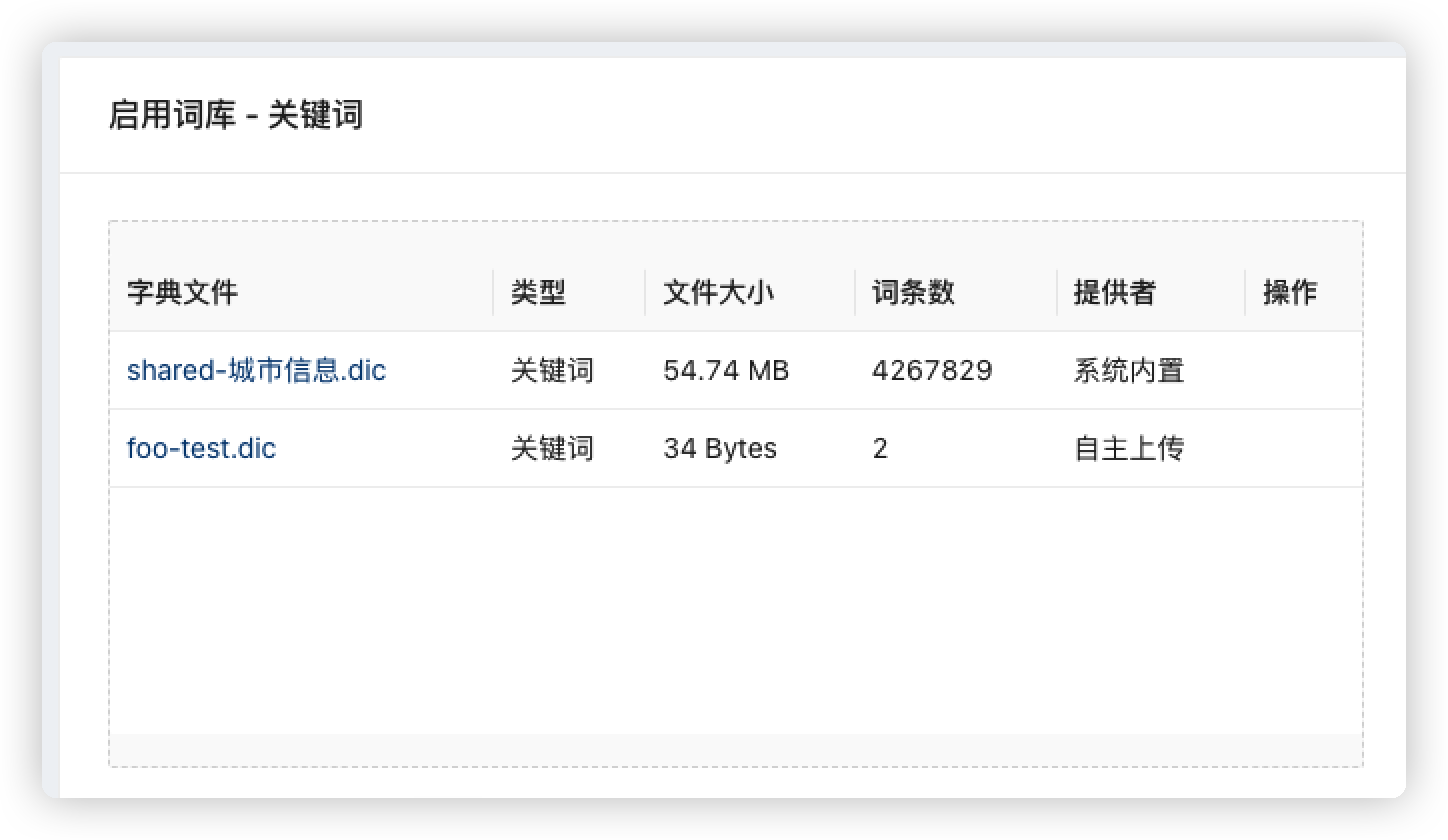
启用共享词典
启用平台内置的【城市信息】词库,涵盖426万国内主要城市地区信息
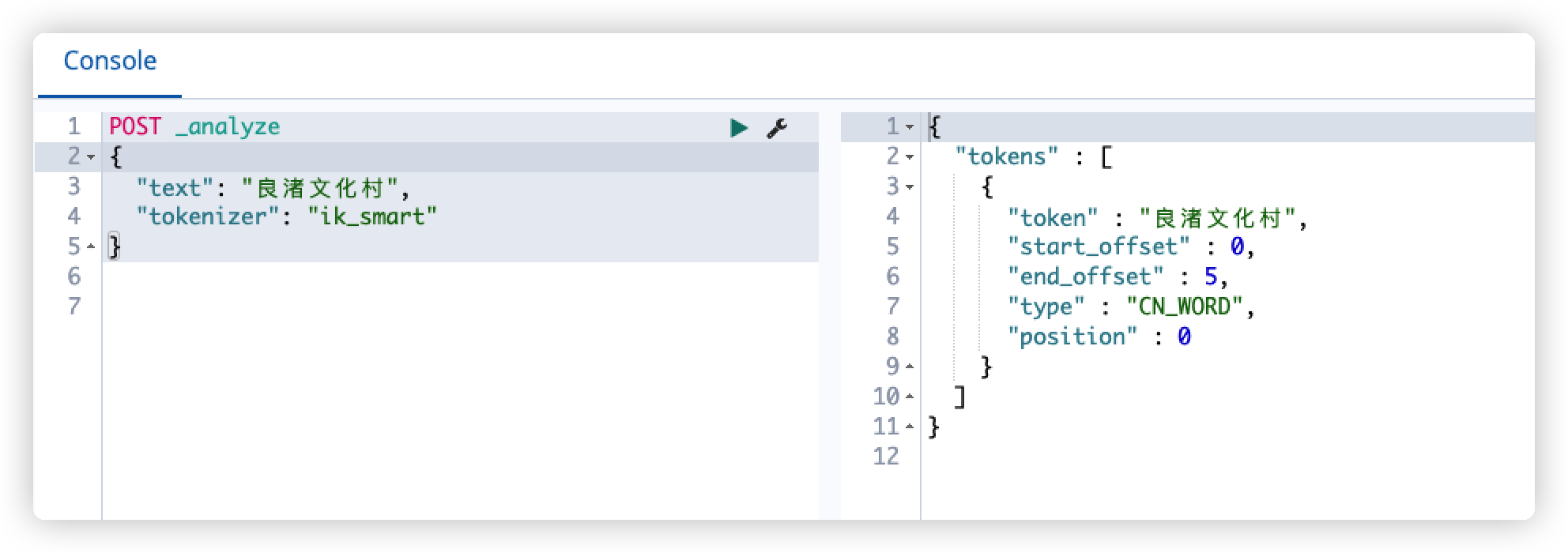
启用后稍等词库更新(一分钟内),再次执行 检查分词效果
自定义上传词库
准备一个简单的自定义词库,如包含如下两个词条
test.dic
莱万多夫司机
马斯切拉诺
将文件拖动到启用词库列表,完成自定义词库上传
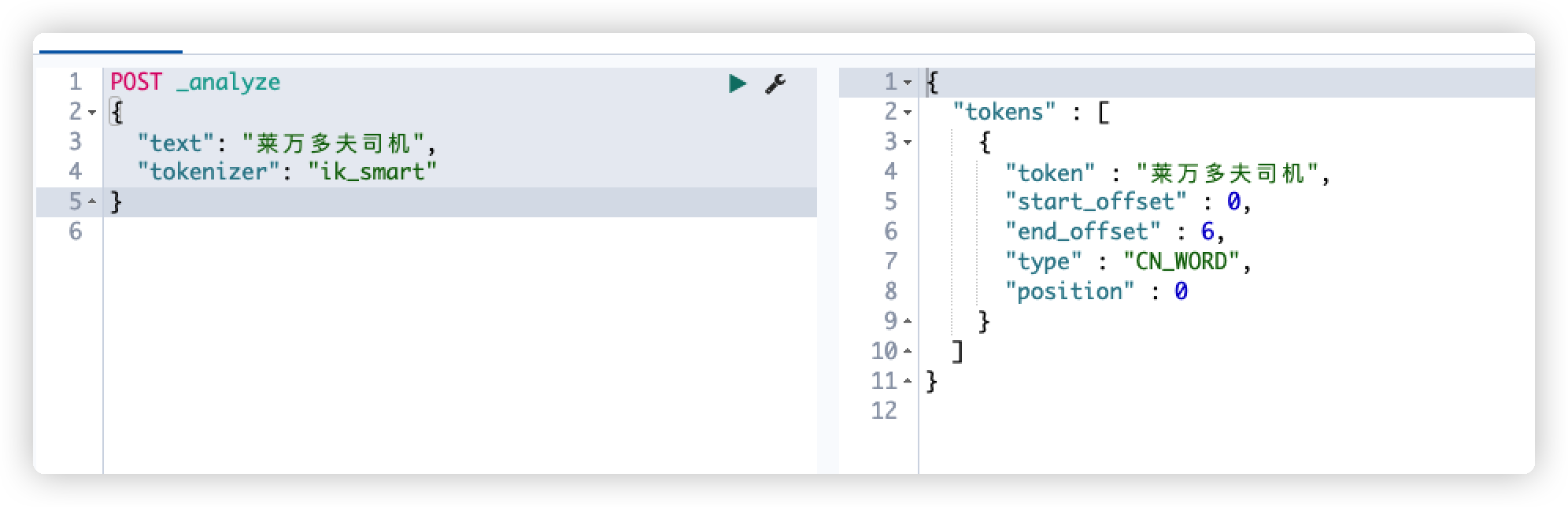
检查分词效果
POST _analyze
{
"text": "莱万多夫司机",
"tokenizer": "ik_smart"
}