基数聚合 cardinality
Cardinality Aggregation
计算不同值的近似计数的单值度量聚合。值可以从文档中的特定字段提取,也可以由脚本生成。
假设您正在为商店销售编制索引,并希望统计与查询匹配的已售出产品的唯一数量:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type"
}
}
}
}
返回结果
{
...
"aggregations" : {
"type_count" : {
"value" : 3
}
}
}
精度控制
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "_doc",
"precision_threshold": 100
}
}
}
}
precision_threshold选项允许以内存换取精度,并定义一个唯一的计数,低于该计数的计数将接近精度。高于此值,计数可能会变得更加模糊。支持的最大值为40000,高于此值的阈值将与40000的阈值具有相同的效果。默认值为3000。
近似值计数
计算精确计数需要将值加载到哈希集并返回其大小。当处理高基数集和/或大值时,这不会扩展,因为所需的内存使用量和节点之间每个shard集的通信需要会占用集群的太多资源。
这种基数聚合基于HyperLogLog++算法,该算法基于具有一些有趣属性的值的哈希值进行计数:
- 可配置精度,其决定如何以内存换取精度,
- 在低基数集合上具有优异的精度,
- 固定内存使用量:无论是否存在数百或数十亿个唯一值,内存使用量仅取决于配置的精度。
对于精度阈值c,我们使用的实现需要大约c*8字节。
下表显示了阈值前后的误差变化情况
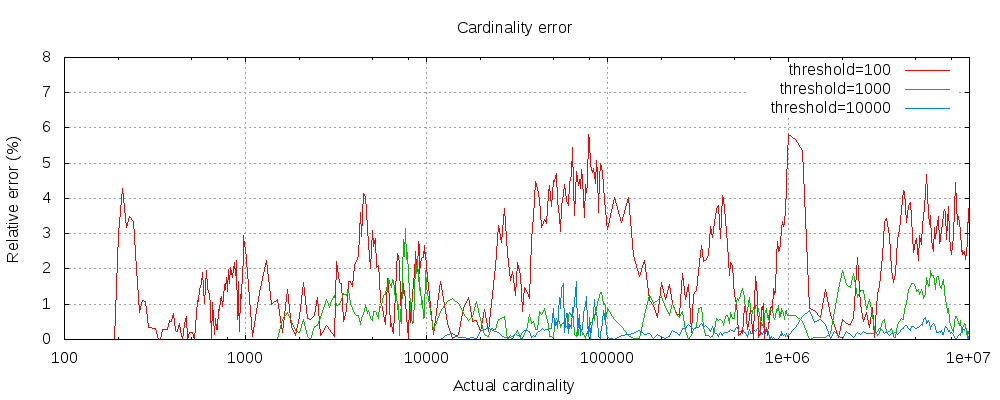
对于所有3个阈值,计数都精确到配置的阈值。虽然不能保证,但情况很可能是这样。实践中的准确性取决于所讨论的数据集。一般来说,大多数数据集显示出一致的良好准确性。还要注意的是,即使阈值低至100,即使在计算数百万项时,误差仍然很低(如上图所示,为1-6%)。
HyperLogLog++算法依赖于哈希值的前导零,数据集中哈希值的精确分布会影响基数的准确性。
还请注意,即使阈值低至100,错误仍然很低,即使在计算数百万项时也是如此。
预计算 hash
对于具有高基数的字符串字段,将字段值的哈希存储在索引中,然后对该字段运行基数聚合可能会更快。这可以通过从客户端提供哈希值来实现,也可以通过使用mapper-murmur3插件让Elasticsearch为您计算哈希值。
预计算散列通常只在非常大和/或高基数字段上有用,因为它节省了CPU和内存。然而,在数字字段上,哈希运算非常快,存储原始值所需的内存与存储哈希值所需内存相同或更少。对于低基数字符串字段也是如此,特别是考虑到这些字段进行了优化,以确保每个段的每个唯一值最多计算一次散列
Script
cardinality 度量支持脚本编写,但由于需要实时计算哈希值,因此性能会受到显著影响。
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script": {
"lang": "painless",
"source": "doc['type'].value + ' ' + doc['promoted'].value"
}
}
}
}
}
这将把脚本参数解释为具有painless语言且没有脚本参数的inline script。要使用存储的脚本,请使用以下语法:
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script" : {
"id": "my_script",
"params": {
"type_field": "_doc",
"promoted_field": "promoted"
}
}
}
}
}
}
Missing value
缺少的参数定义了应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /sales/_search?size=0
{
"aggs" : {
"tag_cardinality" : {
"cardinality" : {
"field" : "tag",
"missing": "N/A"
}
}
}
}
标记字段中没有值的文档将与值为N/a的文档属于同一存储桶。