数值(Numberic)在搜索引擎中通常扮演着重要的角色,例如:
- 等值比较:
x = ? - 大小比较:
x > 1 - 集合判断:
x in ( 1, 3, 5, 8, 9) - 范围查询:
x in [100 .. 200] - 距离计算:
distance(x,y)
如何通过设计优良的数据结构和算法,搭配统一的执行框架高效的满足以上场景,我们从开源引擎 Lucene Point 的设计来展开分析。本文希望通过通俗易懂的图文方式一步步剖析它的原理进而了解其背后的的设计思想,而不是枯燥的理论知识。
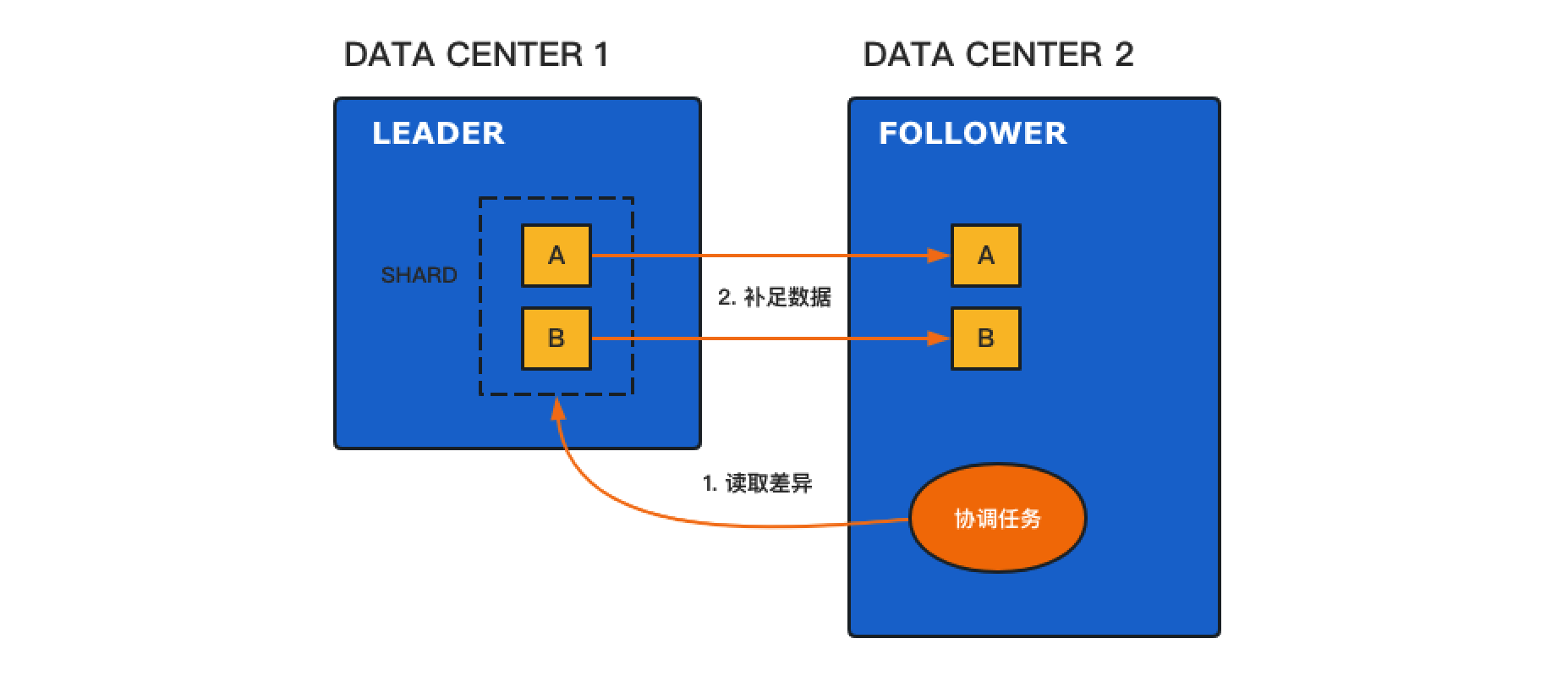
执行框架

如上图,简要来说:
- 构建便于快速查询的核心索引结构:由 binary tree index (point) + Leaf(point,docid映射) 组成。
- 执行检索时基于tree的二分法快速定位匹配的 leaf block。
- 通过leaf block取出对应的文档列表(docid ...)
- 为满足不同的查询场景,visitor抽象了数据的访问方式,用于实现不同query的遍历算法。
- point tree 存放在堆内存,以获取最快的访问速度。
- leaf block 由 point + docid 双数组组成,存放在磁盘。(通过mmap加速)
索引文件结构分析
Leaf Block文件格式总体分为三大块
- meta: 整块索引的元信息
- body: 叶子列表,一个leaf block 由docid,point组成的pair双数组的集合, pair的长度通常为1024。
- foot: 尾部信息

这里我们可以直观的感受到数值数据经过分块后带来了哪些好处:
- 检索复杂度降低,如1亿个整数,通过block打包后降到10W个。
- 提升内存操作效率,在索引创建或加载时,由于block长度统一,整块索引的操作效率要远高于单个数值的操作。
- 节省磁盘存储空间,由于block内数值是排好序的,可以利用各种压缩算法降低存储空间。
1. meta部分

- numDims - 维度,例如IntPoint为1维
- maxPointsInLeafNode - 一个叶子包含多少point, 默认1024
- bytesPerDim - 每个维点字节数, 例如IntPoint为4个字节
- numLeaves - 多少个叶子
- minPackedValue - 最小point value
- maxPackedValue - 最大point value
- pointCount - point总数
- docCount - docid 总数
- packedIndex - 压缩字节的索引(新版本都采用此方式,比legacy index format节约40%空间)
- point 为多维数据结构,提供快速的单维和多维数值范围以及地理空间点形状过滤。
- es 的数值(integer,float,double,long),IP地址,地理位置等字段索引都是point。
- 在搜索时,不同的维度由自身的算法实现。
2. 单个leaf的文件格式

- Count: leaf内包含多少point
- DocIds: 无序的docid数组
- Values: 有序的point数组。
核心源码指引
private void writeIndex(IndexOutput out, int countPerLeaf, int numLeaves, byte[] packedIndex) throws IOException {
CodecUtil.writeHeader(out, CODEC_NAME, VERSION_CURRENT); // 从头部写入
out.writeVInt(numDims); // 存在几个维度
out.writeVInt(countPerLeaf); // 每个叶子Block的个数 (默认1024)
out.writeVInt(bytesPerDim); // 每个维点的字节数 (整数为4)
assert numLeaves > 0;
out.writeVInt(numLeaves); // 叶子节点数
out.writeBytes(minPackedValue, 0, packedBytesLength); // 最小值
out.writeBytes(maxPackedValue, 0, packedBytesLength); // 最大值
out.writeVLong(pointCount); // point值的个数
out.writeVInt(docsSeen.cardinality()); // docid的个数
out.writeVInt(packedIndex.length);
out.writeBytes(packedIndex, 0, packedIndex.length);
}
检索流程
- 加载BKDReader 有多少个dim文件就创建多少个BKDReader,BKDReader通过读取meta部分完成初始化。
- 为leaf blocks构建完全平衡二叉树。根据numLeaves计算深度,从左到右填满树。
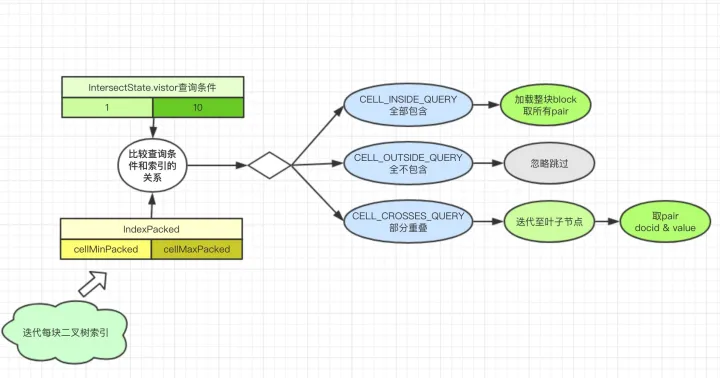
- 检索方式 visitor抽象了访问方式,不同类型的查询Query采用不同的检索访问器。
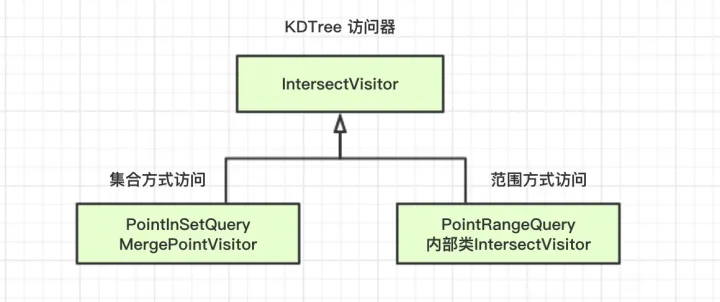
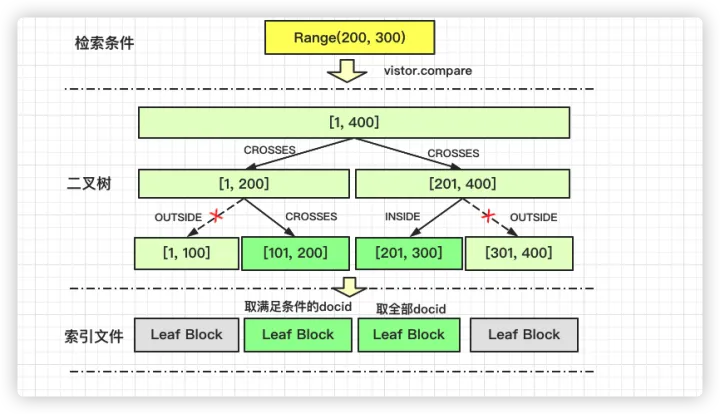
范围检索流程
例如 newRangeQuery(200, 300) 这里访问器采用PointRangeQuery::内部IntersectVistor, 通过一次次索引块的compare取出所有的docid。
集合检索流程
例如 newSetQuery(1, 3, 6, 5, 123, 9999); 和Rang的区别MergePointVisitor会携带查询状态一次遍历完整颗树。
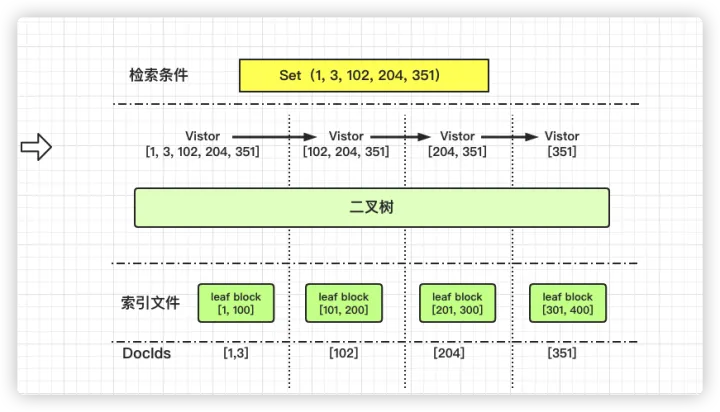
如上图,集合类查询有点像坐公交,出发时携带所有参数,迭代过程如遇到匹配的参数则剔除掉再进入下一个block。
理解了原理,我们便可了解到在超大范围的in操作,数值类的算法复杂度相比term的O(n)就简单了许多。纳速云基于这个特性衍生了 join query , 实现跨表的过滤能力。
取值过程
取docid过程较为简单,seek各个检索满足条件的值到 PointValueQuery.result里
详细算法见BKDReader :: visitCompressedDocValues
总结
Point所采用的的 block k-d trees 是一种简单而强大的数据结构。在索引时,它们是通过递归将要索引的N维点的整个空间划分为越来越小的矩形单元,在递归的每个步骤中,沿着最宽的维度均等地分割。然而,与普通的k-d树不同,一旦单元格中的点数少于预先指定的(默认情况下为1024),k-d trees 就停止递归。
此时,该单元中的所有点都被写入磁盘上的一个leaf block中,该块的起始文件指针被保存到堆内binary tree中。在1维的情况下,这仅仅是所有值的完整排序,划分为相邻的叶块。有的k-d树变体可以支持删除值和重新平衡,但Lucene不需要这些操作,因为它为每段的一次写入设计。
在搜索时,进行相同的递归,在每个level测试所请求的查询条件是否与每个维度分割的左或右子树相交,如果是,则递归。在1维情况下,查询形状只是一个数字范围,而在2D和3D情况下,它是一个地理空间形状(圆形、环形、矩形、多边形、立方体等)
Vistor 抽象了遍历算法,感兴趣的同学可以根据该框架自行扩展,而不会破坏核心的执行框架。